
기간: 2024.03.04 ~ 2024.04.01
개인 순위: 24th
소스 코드는 Github에서 확인할 수 있습니다.
참가 목표
취업 준비로 인해 기간이 일주일 가량 남았을 때 시작했었다. 그럼에도 불구하고 NLP 중 Program Language를 다룰 수 있고 LLM Fine-tuning 수행 경험을 해볼 수 있어 참가하였다.
데이터셋
제공된 데이터는 500개의 문제에 대해 해당 문제를 해결하는 서로 다른 코드 500개로 총 250000(=500x500)개의 C++로 작성된 스크립트 파일이다.
Siamese network로 학습시키기 위해 모든 코드가 데이터셋에 1번 씩만 포함되면 gold similarity(0 or 1)의 비율이 1:1이 되도록 구축하였다.
설명을 용이하게 하기 위해 500개의 문제를 problem 1 ~ 500, 그 문제를 해결하기 위한 코드를 detail 1-1 ~ detail 500-500(문제번호 - 스크립트 파일 번호)이라고 하자. 스크립트 파일 번호가 1 ~ 250까지는 similarity 1을 위해 사용하고, 251 ~ 500은 similarity 0을 위해 사용하였다.
Similarity 1 데이터는 problem 1 ~ 500에 대해 각 문제의 detail의 번호가 125씩 차이가 나도록 짝을 지어 pair를 구성하였다. 따라서 62500(=500x125)개의 pair가 생성된다.
Similarity 0 데이터는 problem의 번호가 250씩 차이나고 detail 번호는 동일하도록 pair를 구성하였다. 즉, detail 1-251과 detail 251-251이 pair로 구성된다. 마찬가지로 62500(=250x250)개의 pair가 생성된다.
이를 코드로 구현하면 다음과 같다.
def make_train_dict():
train_dict = defaultdict(list)
for num_problem in tqdm(range(1, 501), desc="Similarity 1"):
for num_detail in range(1, 126):
code1_path = DATA_PATH / f"train_code/problem{num_problem:0>{3}}/problem{num_problem:0>{3}}_{num_detail}.cpp"
code2_path = DATA_PATH / f"train_code/problem{num_problem:0>{3}}/problem{num_problem:0>{3}}_{num_detail + 125}.cpp"
train_dict["code1_path"].append(code1_path)
train_dict["code2_path"].append(code2_path)
with open(code1_path, "r") as f:
code1 = f.read()
code1 = remove_comments(code1)
with open(code2_path, "r") as f:
code2 = f.read()
code2 = remove_comments(code2)
train_dict["code1"].append(code1)
train_dict["code2"].append(code2)
train_dict["similar"].append(1.0)
for num_problem in tqdm(range(1, 251), desc="Similarity 0"):
for num_detail in range(251, 501):
code1_path = DATA_PATH / f"train_code/problem{num_problem:0>{3}}/problem{num_problem:0>{3}}_{num_detail}.cpp"
code2_path = DATA_PATH / f"train_code/problem{num_problem + 250:0>{3}}/problem{num_problem + 250:0>{3}}_{num_detail}.cpp"
train_dict["code1_path"].append(code1_path)
train_dict["code2_path"].append(code2_path)
with open(code1_path, "r") as f:
code1 = f.read()
with open(code2_path, "r") as f:
code2 = f.read()
train_dict["code1"].append(code1)
train_dict["code2"].append(code2)
train_dict["similar"].append(0.0)
return train_dict
코드에서 주석을 제거하는 전처리도 수행해보았는데, 성능이 더 떨어졌었다.
모델
사전 학습 모델로는 Microsoft의 CodeReviewer를 사용하였다. 해당 모델은 코드 리뷰 시나리오에서 코드 차이를 입력으로 사용하는 사전 훈련 모델이다. 코드 변경을 더 잘 이해하고 생성하기 위한 다운스트림 작업에 사용될 수 있다.

위 그림은 CodeReviewer의 workflow를 보여준다. Comment가 달린 코드와 없는 코드 2개를 입력으로 사용한 뒤 quality estimation, review generation, code refinement 3가지 작업을 수행한다. 그림에서 볼 수 있듯이 해당 모델은 인코더-디코더 구조인데 적절한 코드 임베딩을 생성하여 다운스트림을 수행하기 위해 인코더 부분만 사용하였다.
손실 함수
손실 함수로는 코사인 유사도를 사용하였고, 이에 따라 binary classification을 수행하였다.
위와 같이 가중치를 공유하는 siamese network에 A, B 문장이 입력되고 각각 임베딩 벡터 u, v를 생성한다. 그럼 다음 두 임베딩 벡터의 코사인 유사도를 계산한다. Gold similarity와 손실을 계산하기 위해서는 MSE가 사용되며 수식으로는 다음과 같다.
‖
Cut-off는 0.5로 지정되지 않는다. 모델 학습을 수행할 때 valid set에 대한 평가를 수행하는데, 매 에포크마다 최대의 정확도를 달성할 수 있는 cut-off threshold를 찾는다.
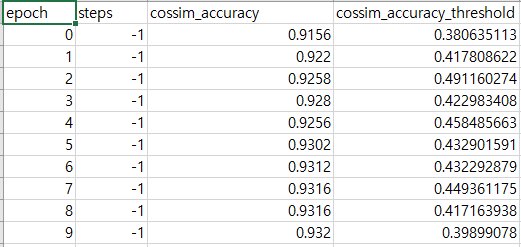
위는 모델 학습시 생성되는 eval csv 파일의 일부분이다. 추론을 수행할 때는 해당 파일에서 threshold를 참고해 label을 예측한다.
향후 계획
데이터셋 구축
데이터셋을 구축할 때 많은 고민이 있었다. 가령 tabular data를 전처리할 때 중복되는 데이터는 제거하지 않는가? 이런 생각이 들어서 모델이 모든 코드를 1번씩만 볼 수 있도록 데이터셋을 구축했다. 또한 Siamese network의 2개의 네트워크가 가중치를 공유하기 때문에 네트워크 A에서 본 데이터는 간접적으로 네트워크 B에도 영향을 주겠다고 생각하여 pair를 구성할 때도 어떤 코드도 A와 B 중 하나에만 입력되도록 구성하였다.
위와 같은 생각이 옳은지는 잘 모르겠다. 모델 학습이란 것이 성능에 따라 결과론적인 부분이기도 하고, 또한 bagging 같은 경우는 일부로 데이터를 중복하여 resampling을 하지 않는가? 따라서 샘플을 중복하여 pair를 구성한다면 그 중복에대한 규칙이 필요할 텐데 그런 부분에 대해서 많은 고민을 했었다.
결론은 siamese network 혹은 가중치를 공유하는 네트워크를 학습시킬 때 효과적으로 학습시킬 수 있는 데이터셋 구축에 대해서 더 알아봐야겠다고 생각했다.
방법론
이 경진대회를 위해 Sentence Transformer을 읽은 후에 CodeReviewer 논문을 읽었다. Mircrosoft의 Github를 보면 CodeReviewer 이전에 CodeBERT, UnixCoder를 제안했었다. 시간이 부족하기도 하고 최신 모델이 성능이 더 좋을 것이라 생각하여 앞선 두 논문은 스킵하고 적용해보지 않았다. 그로 인해 Program Language 처리에 대한 도메인 이해도가 좀 떨어진다는 생각이 들었다. 대회는 끝났지만 두 논문 내용도 블로그에 정리하여 시도해볼 생각이다.