GPT(Generative Pre-trained Transformer)는 2018년 OpenAI에서 발표한 트랜스포머 기반 언어 모델이다. 이 모델은 ELMo(Embeddings from Language Model)와 같이 대규모 말뭉치로 사전 학습된 모델로 다양한 다운스트림 작업에서 우수한 성능을 보인다.
ELMo는 다른 포스팅을 참고
2024.02.06 - [Deep Learning/NLP] - ELMo(Embeddings from Language Model)
ELMo(Embeddings from Language Model)
자료 출처 paper 1. ELMo Bank라는 단어는 Bank Account와 River Bank에서 전혀 다른 의미를 가진다. 그러나 Word2Vec이나 GloVe는 Bank라는 단어를 예를 들어 [0.2, 0.8, -1.2]와 같이 동일한 임베딩 벡터로 표현한다.
ai-junha.tistory.com
GPT는 트랜스포머의 디코더를 여러 층 쌓아 만든 언어 모델이다. 트랜스포머의 인코더는 입력 문장의 특징을 추출하는 데 초점을 두고 있다면, 디코더는 입력 문장과 출력 문장 간의 관계를 이해하고 출력 문장을 생성하는 초점을 두고 있다.
이러한 특성 때문에 디코더를 쌓아 모델을 구성하는 것이 자연어 생성과 같은 언어 모델링 작업에서 더 높은 성능을 발휘한다. GPT는 일반적으로 자연어 생성, 기계 번역, 질의응답, 요약 등 다양한 자연어 처리 작업에 활용된다.
GPT 모델은 다양한 시리즈가 존재한다. 발표 순서대로 GPT-1, 2, 3, 3.5, 4라는 이름으로 알려져 있다. 이 모델들은 거의 동일한 트랜스포머 구조를 사용하며, 버전이 갱신될수록 더 많은 트랜스포모 계층과 데이터를 활용해 학습됐다.
GPT-3의 경우 1750억 개의 매개변수를 갖는 초거대 모델이기 때문에 문장을 생성하는 데 많은 자원을 필요로 한다. 많은 양의 매개변수를 줄이기 위해 OpenAI는 RLHF(Reinforce Learning from Human Feedback) 방법을 도입해 GPT-3.5 모델을 학습했다.
RLHF란 인간의 피드백을 이용하는 강화 학습 방법이다. 이 방법은 인간이 모델이 생성한 결과물을 평가하고, 모델이 좋은 결과물을 생성하면 보상을 주어서 모델을 학습시킨다. 이렇게 인간의 지도를 통해 모델을 학습시키는 방법은 기존의 학습 데이터만 사용하는 것보다 더욱 정확하고 효율적인 모델 학습이 가능해 약 60억 개의 가중치로도 뛰어난 성능을 낼 수 있게 됐다.
GPT-4는 텍스트 데이터에 국한되지 않고 이미지 데이터도 처리할 수 있게 개선돼 더 복잡한 작업을 수행할 수 있게 발전됐다.
GPT-1
GPT-1은 트랜스포머 구조를 바탕으로 한 단방향(Unidirectional) 언어 모델이다. 단방향 언어 모델은 텍스트를 생성할 때 현재 위치에서 이전 단어들에 대한 정보만을 참고해 다음 단어를 예측하는 모델이다. 이러한 방식은 모델의 계산량이 줄어들기 때문에 학습 속도가 빠르고, 모델의 크기가 작아질 수 있다는 장점이 있다.
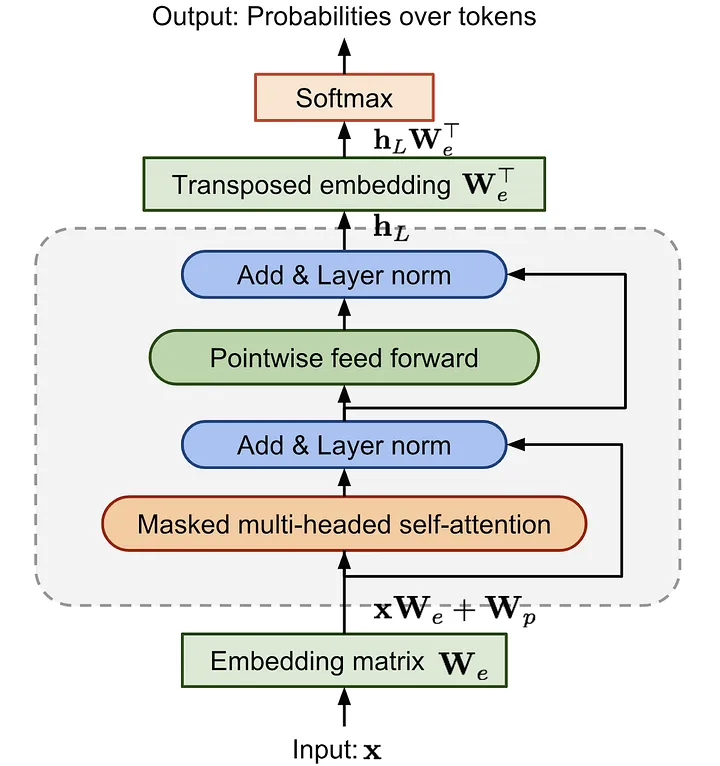
GPT-1은 트랜스포머 구조 중 디코더 부분만 사용하며, 인코더-디코더 간 멀티-헤드 어텐션 부분은 제외한다. 12개의 헤드를 가진 트랜스포머 디코더를 12층 쌓아 모델을 구성하며 약 1억 2천만 개의 매개변수로 학습된다.
GPT-1 모델은 약 4.5GB의 BookCorpus 데이터세트를 사용해 언어 모델을 사전 학습한다. 사전 학습하는 방법은 입력 문장의 일부만 보고 다음 토큰을 예측하도록 하는 언어 모델을 통해 사전 학습한다. 이 과정에서 별도의 레이블이 필요하지 않기 때문에 비지도 학습으로 학습이 이뤄진다.

미세 조정(Fine-Tuning)을 위한 다운스트림 작업에서도 GPT-1은 각 작업에 따라 입출력 주로를 바꾸지 않고 언어 모델을 보조 학습(Auxiliary Learning)해 사용할 수 있다.
다운스트림 작업에서는 일반적인 언어 모델 학습 시 사용되는 손실 함수 외에 다운스트림 작업에서 필요한 추가 손실 함수가 필요하다. 두 개의 손실 함수를 사용해 최적화하면 보조 학습을 통해 언어 모델을 개선하는 동시에, 다운스트림 작업의 목표를 달성하기 위해 필요한 정보를 학습할 수 있다.
GPT-1은 다운스트림 작업에서도 특수 토큰이 사용된다. 문장의 시작을 의미하는 <start>, 두 문장의 경계를 의미하는 <delim>, 문자으이 마지막을 의미하는 <extract> 토큰을 사용한다.
GPT-2
GPT-1과 마찬가지로 트랜스포머 디코더 구조를 사용하며, 48개의 디코더 계층을 사용해 이전 모델보다 더욱 복잡한 패턴을 학습할 수 있게 됐다. GPT-2에서는 약 15억 개의 매개변수를 갖는다. 또한 GPT-1은 입력 문장을 최대 512의 길이만큼 받아 들여 다음 토큰을 예측했지만, GPT-2에서는 1024의 길이까지 입력을 처리할 수 있다.
GPT-2는 미국의 웹사이트에서 스크랩핑한 약 8백만 개의 문서를 사용해 약 40GB 데이터로 사전 학습됐다. 또한, GPT-2는 제로샷 학습이 가능하며 별도의 미세 조정 없이 다운스트림 작업에서도 사용할 수 있게 사전 학습 과정에서 특정한 형식의 데이터를 입력한다.
예를 들어 'GPT는 놀라워요 = GPT is amazing'과 같은 형식의 문장을 학습시킨 후, '번역 한글 문장 ='을 입력하면 번역된 영문이 출력되는 형식으로 작동한다.
GPT-3
GPT-3도 동일한 모델 구조를 사용하지만 매우 규모가 큰 모델로 96개의 헤드를 가진 멀티 헤드 어텐션을 사용하며, 디코더 층도 96개의 층을 사용한다. 멀티 헤드 어텐션 과정에서 연산량을 줄이기 위해 희소 어텐션(Sparse Attention)과 일반 어텐션을 섞어 사용한다. 그리고 토큰 임베딩의 크기도 1600에서 12888로 증가했으며, 2048개의 토큰을 입력으로 사용할 수 있다.
GPT-3은 웹 크롤링, 위키백과, 서적 등에서 수집한 약 45TB의 데이터세트를 이용하여 학습됐다. 이 모델은 다운스트림 작업으로 학습하지 않았지만, 질의응답, 번역, 요약, 문서 생성 등 다양한 다운스트림 작업에서 높은 성능을 보인다.
GPT-3은 큰 모델이기 때문에 매우 느리고 비용이 많이 들어 일반 사용자나 소규모 기업에서 활용하기 어려우며, 사전 학습된 데이터에 기반하여 작동하기 때문에 데이터가 편향돼 있거나 정확하지 않을 경우 오류가 발생할 수 있다.
GPT-3.5
InstructGPT라고 불리며 GPT-3의 모델 구조를 그대로 따르면서도, RLHF를 도입해 모델의 매개변수 수를 줄이고 모델의 자연스러움을 높인 것이 특징이다.
RLHF는 3가지 단계로 나뉜다.

1) Supervised Fine-Tuning(SFT)
데이터세트에서 임의의 프롬프트를 가져온다. 그리고 사람이 이 프롬프트에 대해 적절한 답을 작성한다. 그리고 이 답변을 이용해 GPT-3.5를 미세 조정한다.
2) Reward Model
1)에서 Fine-Tuning된 모델이 생성한 여러 답변 후보들 중 사람이 답변이 잘 된 순서로 랭킹을 부여한다. GPT 모델은 seed에 따라 다른 답변을 생성하므로 내용이 서로 다른 여러 개의 답변이 생성될 수 있다. 그리고 부여된 랭킹을 이용해 Reward Model을 학습한다.
3) Proximal Policy Optimization(PPO)을 이용한 SFT 모델 강화학습
SFT 모델에 여러 사용자들의 입력을 주고, Reward Model과 함꼐 상호 작용하면서 강화학습을 시킨다.
GPT-4
텍스트 데이터뿐만 아니라 이미지 데이터도 인식 가능한 멀티모달(Multimodal) 모델이다. GPT-3.5가 입력으로 최대 4,096개의 토큰을 처리할 수 있었던 반면, GPT-4는 32,768개의 토큰을 입력받을 수 있다.
대규모 다중 작업 언어 이해(Massive Multitask Language Understanding, MMLU) 벤치마크 테스트 결과, GPT-3.5는 약 70%의 성능을 보였지만, GPT-4는 약 85%까지 성능이 향상됐다.
모델 실습
1) 문장 생성
허깅 페이스 트랜스포머스 라이브러리의 GPT-2 모델로 문장을 생성해 본다.
colab에서는 portalocker 패키지를 설치해주어야 한다.
!pip install portalocker -U
문장 생성을 위한 GPT-2 모델의 구조
from transformers import GPT2LMHeadModel
model = GPT2LMHeadModel.from_pretrained(pretrained_model_name_or_path="gpt2")
for main_name, main_module in model.named_children():
print(main_name)
for sub_name, sub_module in main_module.named_children():
print("└", sub_name)
for ssub_name, ssub_module in sub_module.named_children():
print("│ └", ssub_name)
for sssub_name, sssub_module in ssub_module.named_children():
print("│ │ └", sssub_name)transformer
└ wte
└ wpe
└ drop
└ h
│ └ 0
│ │ └ ln_1
│ │ └ attn
│ │ └ ln_2
│ │ └ mlp
...
│ └ 11
│ │ └ ln_1
│ │ └ attn
│ │ └ ln_2
│ │ └ mlp
└ ln_f
lm_head
트랜스포머스 라이브러리의 GPT2LMHeadModel 클래스의 from_pretrained 메서드로 사전 학습된 GPT-2 모델을 불러올 수 있다.
path를 'gpt2'로 지정하면 12개의 디코더 계층을 사용하는 간소화 모델을 불러온다. 48개의 디코더 게층을 사용하는 모델은 'gpt2-xl'로 불러올 수 있다.
모델 구조를 보면 단어 토큰 임베딩(wte), 단어 위치 임베딩(wpe), 드롭아웃(drop), 트랜스포머 디코더 계층(h), 선형 임베딩 및 언어 모델(lm_head)로 구성돼 있다.
GPT-2를 이용한 문장 생성
from transformers import pipeline
generator = pipeline(task="text-generation", model="gpt2")
outputs = generator(
text_inputs="Machine learning is",
max_length=20,
num_return_sequences=3,
pad_token_id=generator.tokenizer.eos_token_id
)
for i, output in enumerate(outputs):
generated_text = output['generated_text']
print(i + 1)
print(generated_text)1
Machine learning is all about the process and the algorithm. This helps us understand how to approach neural networks
2
Machine learning is extremely difficult to develop, because of constraints and unknown technical barriers.
The first
3
Machine learning is more secure than any of the traditional methods at present – a fact that is a key
트랜스포머스 라이브러리는 문장 분류, 문장 생성, 토큰 분류 등 다양한 작업에 대한 전처리, 모델 아키텍처, 후처리를 각각 처리할 수 있는 파이프라인(pipeline) 함수를 제공한다.
파이프라인 클래스는 입력된 task에 model로 적합한 파이프라인을 구축한다.
파이프라인 함수는 설정한 작업을 수행하는 파이프라인 클래스의 인스턴스를 반환한다. 위와 같이 'text-generation'을 입력하면 TextGenerationPipeline 클래스의 인스턴스가 생성된다.
- text_inputs : 생성하려는 문장의 입력을 전달
- max_length : 최대 토큰 수를 제한
- num_return_sequences : 생성할 텍스트 시퀀스 개수를 의미
- pad_token_id : 모델의 자유 생성 여부를 설정. 해당 매개변수를 사용하면 모델 입력된 문장의 문맥을 기반으로 자유롭게 다음 단어나 문장을 생성한다. 만약 pad_token_id를 사용하지 않는다면, 출력된 텍스트의 길이가 정확히 max_length로 설정된 값이 되지 않을 수 있다.
2) 문장 분류
GPT-2 모델은 선형 임베딩(lm_head) 층을 이용해 텍스트 분류 등 다양한 다운스트림 작업에 활용할 수 있다. 이번에는 CoLA(The Corpus of Linguistic Acceptability) 데이터세트를 이용해 모델을 학습해 본다. 이는 문법적으로 올바른 문장과 올바르지 않은 문장을 포함하는 영어 문장 말뭉치 데이터세트이다.
CoLA 데이터세트 불러오기
import torch
from torchtext.datasets import CoLA
from transformers import AutoTokenizer
from torch.utils.data import DataLoader
# 3
def collator(batch, tokenizer, device):
source, labels, texts = zip(*batch)
# 4
tokenized = tokenizer(
texts,
padding="longest",
truncation=True,
return_tensors="pt"
)
# 5
input_ids = tokenized["input_ids"].to(device)
attention_mask = tokenized["attention_mask"].to(device)
labels = torch.tensor(labels, dtype=torch.long).to(device)
return input_ids, attention_mask, labels
# 1
train_data = list(CoLA(split="train"))
valid_data = list(CoLA(split="dev"))
test_data = list(CoLA(split="test"))
# 2
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
epochs = 3
batch_size = 16
device = "cuda" if torch.cuda.is_available() else "cpu"
train_dataloader = DataLoader(
train_data,
batch_size=batch_size,
collate_fn=lambda x: collator(x, tokenizer, device),
shuffle=True,
)
valid_dataloader = DataLoader(
valid_data, batch_size=batch_size, collate_fn=lambda x: collator(x, tokenizer, device)
)
test_dataloader = DataLoader(
test_data, batch_size=batch_size, collate_fn=lambda x: collator(x, tokenizer, device)
)
print("Train Dataset Length :", len(train_data))
print("Valid Dataset Length :", len(valid_data))
print("Test Dataset Length :", len(test_data))Train Dataset Length : 8550
Valid Dataset Length : 526
Test Dataset Length : 515
- CoLA 데이터세트는 train, dev, test로 구성된다.
- GPT-2는 사전 학습 시 패딩 기법을 사용하지 않기 때문에 토크나이저의 특수 토큰 중 패딩 토큰이 따로 포함되어 있지 않다. 따라서 문장 분류 모델을 학습하기 위해 문장의 끝을 의미하는 eos 토큰으로 패딩 토큰을 대체한다.
- collator 함수는 배치를 토크나이저로 토큰화하고, padding, truncation, return_tensors 작업을 수행한다.
- padding에 인자를 longest로 설정하면 가장 긴 시퀀스에 대해 패딩을 적용하고 truncation에 인자를 True로 설정하면 입력 시퀀스 길이가 최대 길이를 초과하는 경우 해당 시퀀스를 자른다. return_tensors에 pt를 입력하면 파이토치 텐서 형태로 결과를 반환한다.
- 토크나이저는 토큰 id(input_ids)와 attention_mask를 반환한다. GPT 모델은 어텐션 마스크를 이용해 입력 문장에서 패딩 부분을 무시하고 실제 단어에 대해 처리한다.
GPT-2 모델 설정
from torch import optim
from transformers import GPT2ForSequenceClassification
model = GPT2ForSequenceClassification.from_pretrained(
pretrained_model_name_or_path="gpt2",
num_labels=2
).to(device)
model.config.pad_token_id = model.config.eos_token_id
optimizer = optim.Adam(model.parameters(), lr=5e-5)
- GPT2ForSequenceClassification 클래스는 기본 GPT-2 모델과 유사하게 작동하지만, 최종 출력 계층이 분류를 위해 미세 조정됐다.
- CoLA 데이터세틑 올바른 문장과 올바르지 않은 문장이 태깅돼 있으므로 num_labels를 2로 설정한다.
- 앞에서도 말했듯이 GPT-2는 사전 학습 시 패딩 기법을 사용하지 않는다. 문장 분류 모델을 학습하기 위해서는 모델이 고정된 길이의 입력을 필요로 하므로 model.config.pad_token_id에 접근하여 이를 eos 토큰으로 대체한다.
GPT-2 모델 학습 및 검증
import numpy as np
from torch import nn
def calc_accuracy(preds, labels):
pred_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
return np.sum(pred_flat == labels_flat) / len(labels_flat)
def train(model, optimizer, dataloader):
model.train()
train_loss = 0.0
for input_ids, attention_mask, labels in dataloader:
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels
)
loss = outputs.loss
train_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss = train_loss / len(dataloader)
return train_loss
def evaluation(model, dataloader):
with torch.no_grad():
model.eval()
criterion = nn.CrossEntropyLoss()
val_loss, val_accuracy = 0.0, 0.0
for input_ids, attention_mask, labels in dataloader:
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels
)
logits = outputs.logits
loss = criterion(logits, labels)
logits = logits.detach().cpu().numpy()
label_ids = labels.to("cpu").numpy()
accuracy = calc_accuracy(logits, label_ids)
val_loss += loss
val_accuracy += accuracy
val_loss = val_loss/len(dataloader)
val_accuracy = val_accuracy/len(dataloader)
return val_loss, val_accuracy
best_loss = 10000
for epoch in range(epochs):
train_loss = train(model, optimizer, train_dataloader)
val_loss, val_accuracy = evaluation(model, valid_dataloader)
print(f"Epoch {epoch + 1}: Train Loss: {train_loss:.4f} Val Loss: {val_loss:.4f} Val Accuracy {val_accuracy:.4f}")
if val_loss < best_loss:
best_loss = val_loss
torch.save(model.state_dict(), "../GPT2ForSequenceClassification.pt")
print("Saved the model weights")Epoch 1: Train Loss: 0.5960 Val Loss: 0.5303 Val Accuracy 0.7232
Saved the model weights
Epoch 2: Train Loss: 0.4694 Val Loss: 0.4658 Val Accuracy 0.7844
Saved the model weights
Epoch 3: Train Loss: 0.3361 Val Loss: 0.4897 Val Accuracy 0.7846
- GPT2ForSequenceClassification 클래스로 학습하면 내부적으로 손실을 계산해 반환한다. 그러므로 train 함수로 모델 학습 시 손실은 모델 outputs의 loss 속성으로 가져온다.
- 모델 평가 시 CrossEntropyLoss 함수로 모델을 평가해 본다. 모델에서 반환하는 손실 값이 아닌, logits과 label로 손실을 계산한다. 추가적으로 calc_accuracy 함수로 정확도도 계산한다.
모델 평가
model = GPT2ForSequenceClassification.from_pretrained(
pretrained_model_name_or_path="gpt2",
num_labels=2
).to(device)
model.config.pad_token_id = model.config.eos_token_id
model.load_state_dict(torch.load("../GPT2ForSequenceClassification.pt"))
test_loss, test_accuracy = evaluation(model, test_dataloader)
print(f"Test Loss : {test_loss:.4f}")
print(f"Test Accuracy : {test_accuracy:.4f}")Test Loss : 0.5494
Test Accuracy : 0.7456
'책 > 파이토치 트랜스포머를 활용한 자연어 처리와 컴퓨터비전 심층학습' 카테고리의 다른 글
| 07 트랜스포머 (4) BART (0) | 2024.02.09 |
|---|---|
| 07 트랜스포머 (3) BERT (0) | 2024.02.07 |
| 07 트랜스포머 (1) Transformer (0) | 2024.01.12 |
| 06 임베딩 (3) CNN (0) | 2024.01.11 |
| 06 임베딩 (2) RNN (0) | 2024.01.11 |


