YOLOv8 모델로 포즈 추정을 간단하게 실습해본다. v8은 v5의 구조를 개선한 모델로 v6처럼 앵커 프리 구조를 사용해 추론 속도를 향상시켰다. 또한 모자이크 합성 이미지로 학습을 수행하는 경우 성능이 저하되는 문제가 발생하는데, v8은 10에폭만 적용해 과대적합을 방지해 성능을 개선했다.
YOLO 모델을 사용하기 위해서는 ultralytics 라이브러리를 설치해야한다. 이는 파이토치와 OpenCV 기반으로 동작한다.
!pip install ultralytics
설정
from pathlib import Path
from google.colab.patches import cv2_imshow
import cv2
import torch
from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator
다른 포스팅과 마찬가지로 책에서 제공하는 데이터를 사용한다. 따로 모델 학습을 수행하진 않고 사전 학습된 모델과 동영상 데이터 하나로 실습을 진행한다.
포즈 추정 모델 불러오기
- YOLO 클래스를 통해 사전 학습된 yolov8m-pose 모델을 불러온다. 지원 되는 모델은 yolov8n, yolov8s, yolov8m, yolov8l, yolov8x로 5개다.
- suffix에 아무것도 입력하지 않으면 기본 검출 모델을 불러온다. -seg, -cls, -pose는 각각 세그멘테이션, 분류, 포즈 추정 모델을 불러온다.
- MS COCO 데이터셋을 활용해 학습했으므로 80개의 클래스를 예측할 수 있다. 포즈 추정 모델의 경우 사람 객체만 예측한다.
model = YOLO("../models/yolov8m-pose.pt")
비디오 파일 불러오기
- VideoCapture 클래스는 비디오 파일 또는 카메라 장치를 불러온다. 문자열을 입력하면 파일 경로로 간주해 비디오 파일을 읽는다. 0이나 1과 같은 정수를 입력하는 경우 카메로 장치 번호로 간주해 카메라를 불러온다.
- CAP_PROP_FPS는 초당 프레임 수를 나타내며, CAP_PROP_FRAME_COUNT는 전체 프레임 수를 나타낸다.
- 작업이 끝나면 꼭 release 메서드로 VideoCapture 클래스를 닫고 메모리를 해제해야 한다.
capture = cv2.VideoCapture(str(DATA_PATH / 'datasets' / 'woman.mp4'))
fps = capture.get(cv2.CAP_PROP_FPS)
total_frames = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))
total_seconds = total_frames / fps
print(f"FPS: {fps}")
print(f"Total Frames: {total_frames}")
print(f"Total Seconds: {total_seconds}")
capture.release()
FPS: 25.0
Total Frames: 517
Total Seconds: 20.68
모델 추론
- source는 추론하려는 이미지나 프레임을 전달하다. iou는 중복된 바운딩 박스를 제거하는 threshold이다. conf는 클래스 점수 threshold이며 설정한 값보다 낮은 값은 제거된다.
- yolov8 모델은 배치 형태로 이미지를 입력받을 수 있다. 예제에서는 하나의 프레임만 전달하므로 results 값의 첫 번째 인덱스만 사용한다.
def predict(frame, iou=0.7, conf=0.25):
results = model(
source=frame,
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu"),
iou=iou, # 중복된 바운딩 박스를 제거하는 threshold, 너무 높은 값으로 설정하면 중복된 바운딩 박스가 제거되지 않을 수 있다.
conf=conf, # class score threshold
verbose=False,
)
result = results[0]
return result
바운딩 박스 시각화
- 여러 객체에 대한 바운딩 박스가 존재할 수 있으니 for문으로 box 정보를 받아온다. result.boxes에는 boxes, cls, conf, data 등의 속성이 있다.
def draw_boxes(result, frame, color=(0, 0, 255), thickness=1):
for boxes in result.boxes:
x1, y1, x2, y2, score, class_id = boxes.data.squeeze().cpu().numpy()
cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), color, thickness)
return frame
모델 추론 및 시각화 적용
5초 간격을 두어 시각화를 수행한다. 출력 이미지 중 하나만 포스팅하였다.
capture = cv2.VideoCapture(str(DATA_PATH / 'datasets' / 'woman.mp4'))
fps = capture.get(cv2.CAP_PROP_FPS)
interval_seconds = 5
interval_frames = int(fps * interval_seconds)
while True:
ret, frame = capture.read()
if not ret:
break
current_frame = int(capture.get(cv2.CAP_PROP_POS_FRAMES))
if current_frame % interval_frames == 0:
result = predict(frame)
frame = draw_boxes(result, frame)
cv2_imshow(frame)
capture.release()
cv2.destroyAllWindows()
키 포인트 시각화
- Annotator 클래스는 이미지와 선 두께를 전달해 인스턴스를 생성한다.
- 키 포인트를 사람의 수만큼 존재할 수 있으므로 반복문으로 구성하며, kpts 메서드에 값을 전달한다. 키 포인트 시각화 메서드는 (17, 3) 형태의 데이터를 입력받는다. MS COCO 키 포인트 데이터셋은 17개의 신체 부위를 예측할 수 있다. 그러므로 키 포인트 데이터 구조는 [x, y, conf] 구조로 반환된다.
- 시각화 메서드는 항상 정확도가 0.5 이상인 키 포인트만 시각화한다. 모든 키 포인트를 시각화하려면 주석을 해제하면된다.
키 포인트 의미는 다음과 같다.
| id | 의미 | id | 의미 |
| 0 | 코 | 9 | 왼쪽 손목 |
| 1 | 왼쪽 눈 | 10 | 오른쪽 손목 |
| 2 | 오른쪽 눈 | 11 | 왼쪽 골반 |
| 3 | 왼쪽 귀 | 12 | 오른쪽 골반 |
| 4 | 오른쪽 귀 | 13 | 왼쪽 무릎 |
| 5 | 왼쪽 어깨 | 14 | 오른쪽 무릎 |
| 6 | 오른쪽 어깨 | 15 | 왼쪽 발목 |
| 7 | 왼쪽 팔꿈치 | 16 | 오른쪽 발목 |
| 8 | 오른쪽 팔꿈치 |
def draw_keypoints(result, frame, color=(0, 0, 255)):
annotator = Annotator(frame, line_width=1)
for kps in result.keypoints:
kps = kps.data.squeeze()
annotator.kpts(kps) # kps shape -> [17, 3], 17개 신체 부위에 대한 (x, y, conf)
nkps = kps.cpu().numpy()
# nkps[:, 2] = 1
# annotator.kpts(nkps) 주석은 정확도가 0.5 미만은 키 포인트도 시각화
for idx, (x, y, score) in enumerate(nkps):
if score > 0.5:
cv2.circle(frame, (int(x), int(y)), 3, color, cv2.FILLED)
cv2.putText(frame, str(idx), (int(x), int(y)), cv2.FONT_HERSHEY_COMPLEX, 1, color, 1)
return framecapture = cv2.VideoCapture(str(DATA_PATH / 'datasets' / 'woman.mp4'))
fps = capture.get(cv2.CAP_PROP_FPS)
interval_seconds = 5
interval_frames = int(fps * interval_seconds)
while True:
ret, frame = capture.read()
if not ret:
break
current_frame = int(capture.get(cv2.CAP_PROP_POS_FRAMES))
if current_frame % interval_frames == 0:
result = predict(frame)
frame = draw_boxes(result, frame)
frame = draw_keypoints(result, frame)
cv2_imshow(frame)
capture.release()
cv2.destroyAllWindows()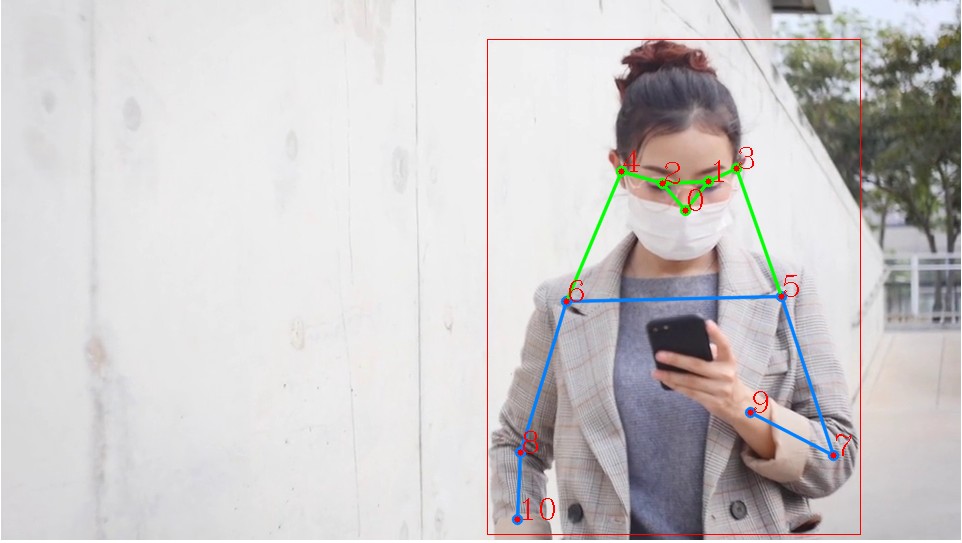
'책 > 파이토치 트랜스포머를 활용한 자연어 처리와 컴퓨터비전 심층학습' 카테고리의 다른 글
| 10 비전 트랜스포머 (2) Swin Transformer pytorch 실습 (0) | 2024.03.11 |
|---|---|
| 10 비전 트랜스포머 (1) ViT (0) | 2024.03.07 |
| 09 객체 탐지 (7) YOLO (0) | 2024.03.05 |
| 09 객체 탐지 (6) Mask R-CNN pytorch 실습 (0) | 2024.03.02 |
| 09 객체 탐지 (5) Mask R-CNN (0) | 2024.03.02 |



