Grad-CAM(Gradient-weighted Class Activation Map)이란 설명 가능한 인공지능(eXplainable Artificial Intelligence, XAI) 기술 중 하나로, 딥러닝 모델의 내부 동작 원리를 시각화하는 방법이다.
딥러닝 모델이 이미지 분류와 같은 작업을 수행하기 위해서는 입력 이미지에서 중요한 영역을 파악해 예측해야 한다. 하지만 이러한 예측 과정은 블랙박스 문제를 유발한다. 블랙박스 문제란 딥러닝 모델이 어떻게 입력 데이터를 처리해 예측을 내리는지 이해하기 어려운 문제를 의미한다.
설명 가능한 인공지능은 이러한 문제를 해결하기 위해 고안된 방법론으로, 모델 내부 작동 방식을 분석해 결과를 해석하고, 인공지능 모델의 동작 방식을 설명할 수 있는 방법을 제공한다.
1. 클래스 활성화 맵
클래스 활성화 맵(Class Activation Map, CAM)은 딥러닝 모델에서 특정 클래스와 관련된 입력 이미지 영역을 시각화하는 방법이다.
1.1 클래스 활성화 맵 생성 방식
합성곱 신경망의 마지막 합성곱 계층에 전역 평균 풀링(Global Average Pooling, GAP)를 적용해 특징 맵의 채널수와 동일한 길이를 가지는 벡터를 얻는다. 그런 다음 이를 분류기에 전달하고, 이 때 사용한 분류기의 매개변수가 출력 클래스에 대한 특징값 가중치가 된다.

위의 그림과 같이 특징 맵의 채널 수가 6고 클래스가 4개라면 분류기는 [6, 4]의 매개변수를 갖게된다. 그러면 [6, 1]의 크기를 가지는 각 클래스에 대한 가중치의 모음이 4개가 있다고 이해할 수 있다. 그리고 이 벡터의 각 요소들이 어떤 클래스 c에 대한 각 채널에 대응하면 가중치 스칼라값들이라고 이해할 수 있다. 각각에 대응하는 특징맵과 가중치를 곱한 뒤 동일 위치 픽셀별로 더해주어 어떤 클래스 c에 대한 클래스 활성화 맵(히트맵)을 얻을 수 있다.
수식으로 표현하면 다음과 같다.
Lc(i,j)=∑kwckfk(i,j)
- fk(i,j) : f는 특징 맵을 의미하며, k는 채널 수를 의미한다. i와 j는 클래스 활성화 맵의 행과 열을 의미한다. 위의 그림에서 최종적으로 얻은 히트맵이 클래스 활성화 맵을 의미한다.
- wck : 클래스 c에 대한 채널의 특징 맵 분류 가중치. 위의 그림에서 weight 1~6에 해당
1.2 클래스 활성화 맵 적용
사전 학습된 ResNet-18의 특징 맵을 활용해 클래스 활성화 맵을 구현해 본다.
import torch
from torch import nn
from torch.nn import functional as F
from torchvision import models, transforms
from PIL import Image
from urllib.request import urlretrieve
import matplotlib.pyplot as plt
ResNet-18 모델 특징 추출
- 사전 학습된 모델을 불러오고 평균 풀링과 완전 연결 계층을 제외하고 특징만 연산하는 계층들을 features에 저장한다.
model = models.resnet18(weights="ResNet18_Weights.IMAGENET1K_V1").eval()
features = nn.Sequential(*list(model.children())[:-2])
참고로 모델 구조는 다음과 같다.
for name, module in model.named_children():
print(name)conv1
bn1
relu
maxpool
layer1
layer2
layer3
layer4
avgpool
fc
특징 맵과 가중치 추출
- transform을 정의하고 이미지를 다운받은 뒤 transform을 적용해준다.
- model의 output은 shape은 [1, 1000]으로 argmax를 적용하여 클래스 인덱스를 얻는다.
- 모델의 fc layer의 가중치의 shape은 [1000, 512]이다. 클래스 인덱스를 사용해 해당 클래스의 가중치를 얻고 feature와의 곱연산을 위해 [512, 1, 1]로 변경해준다.
- features를 통해 이미지에 대한 특징 맵을 features_output에 저장한다.
transform = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
url = "https://raw.githubusercontent.com/pytorch/hub/master/images/dog.jpg"
filename = "dog.jpg"
urlretrieve(url, filename)
img = Image.open(filename)
target = transform(img).unsqueeze(0)
output = model(target)
class_idx = int(output.argmax())
weights = model.fc.weight[class_idx].reshape(-1, 1, 1)
features_output = features(target).squeeze()
print(weights.shape)
print(features_output.shape)torch.Size([512, 1, 1])
torch.Size([512, 7, 7])
클래스 활성화 맵 생성
- 클래스 활성화 맵을 계산한 뒤 interpolate 메서드를 통해 입력 이미지 크기와 동일한 크기로 변경한다.
- input의 차원을 늘려주는 이유는 interpolate 메서드가 4차원의 입력을 받기 때문이다.
- PIL Image 타입은 [width, height]이다. numpy를 시각화 할 때는 [height, width]를 기대하기 때문에 size를 이미지 차원의 역순으로 입력한다.
cam = features_output * weights # 512, 7, 7
cam = torch.sum(cam, dim=0) # 7, 7
cam = F.interpolate(
input=cam.unsqueeze(0).unsqueeze(0),
size=img.size[::-1],
mode="bilinear",
).squeeze().detach().numpy()img.size # width, height
(1546, 1213)
cam.shape
(1213, 1546)
클래스 활성화 맵 시각화
plt.imshow(img)
plt.imshow(cam, cmap="jet", alpha=0.5)
plt.axis("off")
plt.show()
보간을 bilinear 방식이 아닌 nearest를 사용하면 다음과 같다.

CAM의 단점은 GAP를 반드시 사용하고 그 뒤에 FC layer가 포함되어야 한다. 또한 FC layer의 weight을 구하기 위해 학습을 시켜야 한다. 이러한 점을 극복하기 위해 Grad-CAM이 등장하였다.
2. Grad-CAM
GAP를 사용하지 않고 마지막 합성곱 계층의 기울기 값을 사용한다.
수식은 다음과 같다.
Lc(i,j)=ReLU(∑kackfk(i,j))
w대신 a를 사용하는 것이 차이점이다. ack의 수식은 다음과 같다.
ack=1Z∑i∑j∂yc∂fk(i,j)
yc : 합성곱 계층의 출력값 중 클래스 c에 대한 점수
Z : 특징 맵의 픽셀 수, 1Z∑i∑j은 GAP와 동일한 역할을 한다.
활성화 맵의 음수는 클래스와 상관없는 부분이므로 ReLU를 적용하여 제거한다.
2.1 Grad-CAM 적용
사전학습된 ResNet-18과 후크를 활용해 실습한다. 후크란 특정 이벤트가 발생했을 때 다른 코드를 실행하는 기술을 의미한다.
순전파와 역전파 후크 등록
- 초기화시 register_hook이 실행된다.
- 마지막 합성곱 계층을 확인하기 위해 main, sub를 받아오는데 ResNet-18을 기준으로 main은 layer4이고 sub는 conv2가 된다.
- 마지막 합성곱 계층을 찾으면 module의 순방향시 발생하는 register_forward_hook과 역방향시 발생하는 register_full_backward_hook 메서드를 사용해 feature_map과 gradient를 받아와 저장한다.
class GradCAM:
def __init__(self, model, main, sub):
self.model = model.eval()
self.register_hook(main, sub)
def register_hook(self, main, sub):
for name, module in self.model.named_children():
if name == main:
for sub_name, sub_module in module[-1].named_children():
if sub_name == sub:
sub_module.register_forward_hook(self.forward_hook)
sub_module.register_full_backward_hook(self.backward_hook)
def forward_hook(self, module, input, output):
self.feature_map = output
def backward_hook(self, module, grad_input, grad_output):
self.gradient = grad_output[0] # 기울기 출력값은 튜플로 감싸인 텐서이므로 첫 번쨰 텐서만 반환
Grad-CAM 생성
- output으로 부터 one-hot encoded 벡터를 만든다.
- output의 backward를 계산할 때 gradient를 onehot으로 지정한다.
- 손실함수가 L, 모델의 출력이 y일 때 그래디언트는 ∂L∂y이다. gradient를 직접 지정하면, ∂L∂y=one−hot으로 계산하게 된다. 이렇게하면 특정 클래스에 대해 그래디언트를 강화할 수 있다.
def __call__(self, x):
output = self.model(x) # [N, 1000]
index = output.argmax(axis=1)
onehot = torch.zeros_like(output)
for i in range(output.size(0)):
onehot[i][index[i]] = 1
self.model.zero_grad()
output.backward(gradient=onehot, retain_graph=True)
a_k = torch.mean(self.gradient, dim=(2, 3), keepdim=True) # [N, 512, 1, 1]
grad_cam = torch.sum(a_k * self.feature_map, dim=1) # [N, 7, 7]
grad_cam = torch.relu(grad_cam)
return grad_cam
GradCAM.__call__ = __call__
Grad-CAM 시각화
IMAGE_PATH = ROOT_PATH / "datasets" / "images"
files = list(IMAGE_PATH.glob("*.jpg"))
transform = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
),
]
)
images, tensors = [], []
for file in files:
image = Image.open(file)
images.append(image)
tensors.append(transform(image))
tensors = torch.stack(tensors)
model = GradCAM(
model=models.resnet18(weights="ResNet18_Weights.IMAGENET1K_V1"),
main="layer4",
sub="conv2"
)
grad_cams = model(tensors)
for idx, image in enumerate(images):
grad_cam = F.interpolate(
input=grad_cams[idx].unsqueeze(0).unsqueeze(0),
size=image.size[::-1],
mode="bilinear",
).squeeze().squeeze().detach().numpy()
plt.imshow(image)
plt.imshow(grad_cam, cmap="jet", alpha=0.5)
plt.axis("off")
plt.show()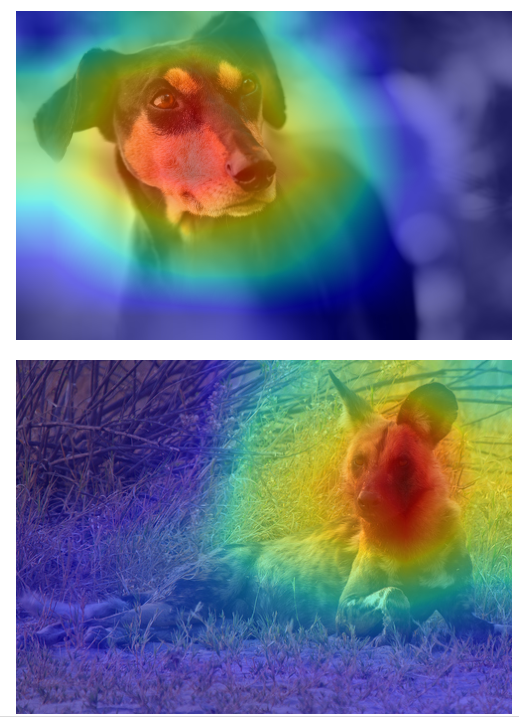
'책 > 파이토치 트랜스포머를 활용한 자연어 처리와 컴퓨터비전 심층학습' 카테고리의 다른 글
| 09 객체 탐지 (2) Faster R-CNN pytorch 실습 (0) | 2024.02.20 |
|---|---|
| 09 객체 탐지 (1) Faster R-CNN (0) | 2024.02.19 |
| 08 이미지 분류 (3) ResNet (0) | 2024.02.15 |
| 08 이미지 분류 (2) VGG (0) | 2024.02.14 |
| 08 이미지 분류 (1) AlexNet (0) | 2024.02.13 |



