CvT(Convolutional Vision Transformer)의 이론적인 내용은 이전 포스팅에서 확인할 수 있다.
2024.03.12 - [논문 리뷰] - [논문 리뷰] CvT: Introducing Convolutions to Vision Transformers
ViT, Swin Transformer와 마찬가지로 허깅페이스 라이브러리로 사전 학습된 CvT 모델을 FashionMNIST 데이터셋으로 간단한 fine tuning 실습을 진행한다. 코드가 거의 동일하기 때문에 변경점과 모델 구조 등을 알아보고 평가 결과만 확인한다.
이미지 프로세서
"microsoft/cvt-21" 모델은 이미지 크기를 조절할 때 shortest_edge 키를 사용해 전처리를 진행한다.
shortest_edge는 이미지의 height과 width 중 더 작은 값을 의미하며, "microsoft/cvt-21" 모델은 모든 입력 이미지의 크기를 가장 짧은 이미지 길이로 정규화해 사용한다.
import torch
from torchvision import transforms
from transformers import AutoImageProcessor
image_processor = AutoImageProcessor.from_pretrained(
pretrained_model_name_or_path="microsoft/cvt-21"
)
transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Resize(
size=(
image_processor.size["shortest_edge"],
image_processor.size["shortest_edge"]
)
),
transforms.Lambda(lambda x: torch.cat([x, x, x], 0)),
transforms.Normalize(
mean=image_processor.image_mean,
std=image_processor.image_std
)
]
)
CvT 모델 불러오기
ImageNet-1K 데이터셋으로 사전 학습된 CvT 모델을 불러온다.
from transformers import CvtForImageClassification
model = CvtForImageClassification.from_pretrained(
pretrained_model_name_or_path="microsoft/cvt-21",
num_labels=len(train_dataset.classes),
id2label={idx: label for label, idx in train_dataset.class_to_idx.items()},
label2id=train_dataset.class_to_idx,
ignore_mismatched_sizes=True
)
CvT 모델은 Swin과 다르게 classifier 이전에 pooler가 존재하지 않는데, 이는 이미 합성곱 계층을 활용해 지역 특징 정보와 전역 정보를 파악하므로 풀링을 적용하지 않는다.
for main_name, main_module in model.named_children():
print(main_name)
for sub_name, sub_module in main_module.named_children():
print("└", sub_name)
for ssub_name, ssub_module in sub_module.named_children():
print(" └", ssub_name)
for sssub_name, sssub_module in ssub_module.named_children():
print(" └", sssub_name)cvt
└ encoder
└ stages
└ 0
└ 1
└ 2
layernorm
classifier
- 각 스테이지는 크게 CvtEmbeddings와 Cvtlayer로 구성된다.
- 224x224 크기의 으미지에 CvtEmbeddings를 적용하면 (224 - 7 + 2 * 2)/4 + 1=56.25로 56x56 크기의 텐서가 생성된다.
- 출력 채널의 크기가 64이므로 [N, 64, 56, 56]의 텐서가 반환된다.
- Key, Value의 다운샘플링을 위해 stride=2로 설정된 것을 확인할 수 있다.
stages = model.cvt.encoder.stages
print(stages[0])CvtStage(
(embedding): CvtEmbeddings(
(convolution_embeddings): CvtConvEmbeddings(
(projection): Conv2d(3, 64, kernel_size=(7, 7), stride=(4, 4), padding=(2, 2))
(normalization): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(dropout): Dropout(p=0.0, inplace=False)
)
(layers): Sequential(
(0): CvtLayer(
(attention): CvtAttention(
(attention): CvtSelfAttention(
(convolution_projection_query): CvtSelfAttentionProjection(
(convolution_projection): CvtSelfAttentionConvProjection(
(convolution): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(normalization): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(linear_projection): CvtSelfAttentionLinearProjection()
)
(convolution_projection_key): CvtSelfAttentionProjection(
(convolution_projection): CvtSelfAttentionConvProjection(
(convolution): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=64, bias=False)
(normalization): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(linear_projection): CvtSelfAttentionLinearProjection()
)
(convolution_projection_value): CvtSelfAttentionProjection(
(convolution_projection): CvtSelfAttentionConvProjection(
(convolution): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=64, bias=False)
(normalization): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(linear_projection): CvtSelfAttentionLinearProjection()
)
(projection_query): Linear(in_features=64, out_features=64, bias=True)
(projection_key): Linear(in_features=64, out_features=64, bias=True)
(projection_value): Linear(in_features=64, out_features=64, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(output): CvtSelfOutput(
(dense): Linear(in_features=64, out_features=64, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
)
(intermediate): CvtIntermediate(
(dense): Linear(in_features=64, out_features=256, bias=True)
(activation): GELU(approximate='none')
)
(output): CvtOutput(
(dense): Linear(in_features=256, out_features=64, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(drop_path): Identity()
(layernorm_before): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(layernorm_after): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
)
)
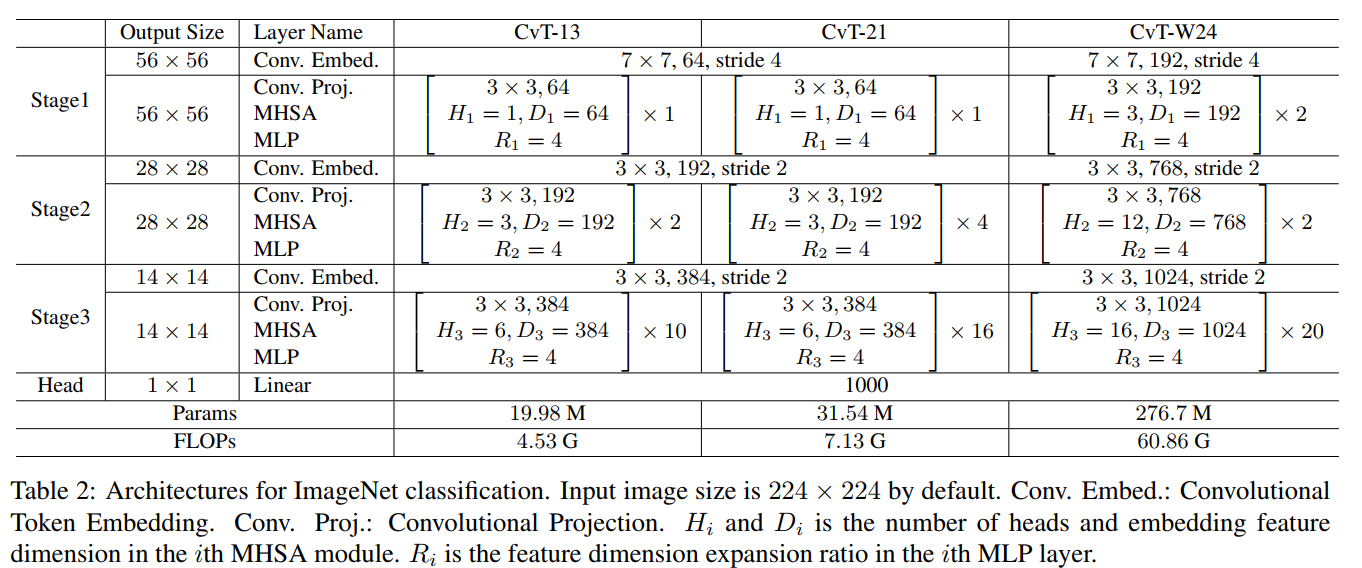
위의 테이블에서 CvT-21 모델의 스테이지 1에서 Conv Embedding의 출력 채널 차원은 64이고, MHSA의 출력 차원도 64임을 알 수 있다. Embedding의 출력 채널 차원이 64인 것은 위에서 확인 했으니 어텐션에 대한 출력 차원을 확인해보자.
batch = next(iter(train_dataloader))
print("이미지 차원 :", batch["pixel_values"].shape)
patch_emb_output = stages[0].embedding(batch["pixel_values"])
print("패치 임베딩 차원 :", patch_emb_output.shape)
batch_size, num_channels, height, width = patch_emb_output.shape
hidden_state = patch_emb_output.view(batch_size, num_channels, height * width).permute(0, 2, 1)
print("셀프 어텐션 입력 차원 :", hidden_state.shape)
attention_output = stages[0].layers[0].attention.attention(hidden_state, height, width)
print("셀프 어텐션 출력 차원 :", attention_output.shape)이미지 차원 : torch.Size([32, 3, 224, 224])
패치 임베딩 차원 : torch.Size([32, 64, 56, 56])
셀프 어텐션 입력 차원 : torch.Size([32, 3136, 64])
셀프 어텐션 출력 차원 : torch.Size([32, 3136, 64])
모델 학습 코드는 생략하고 평가 결과만 확인하면 다음과 같다.
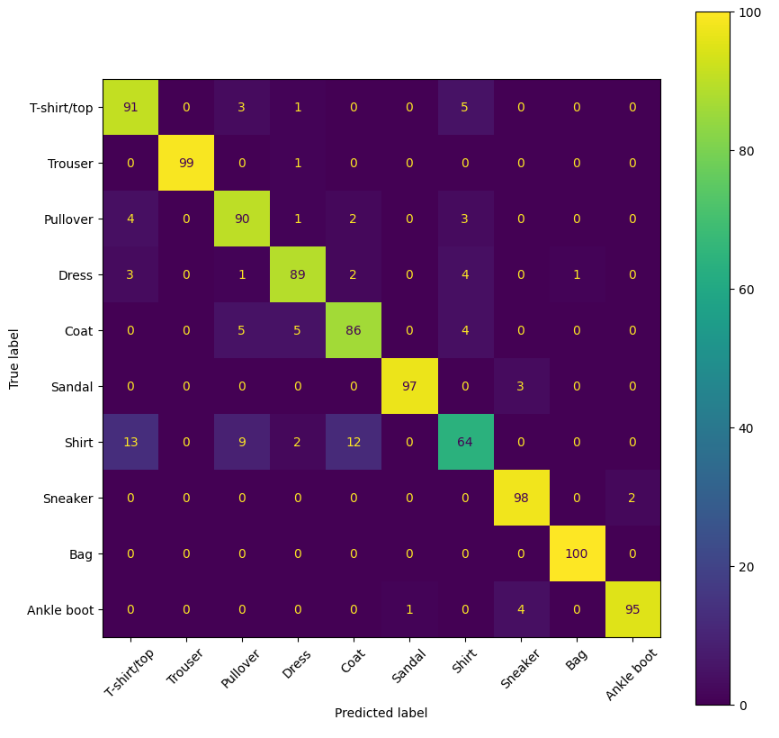
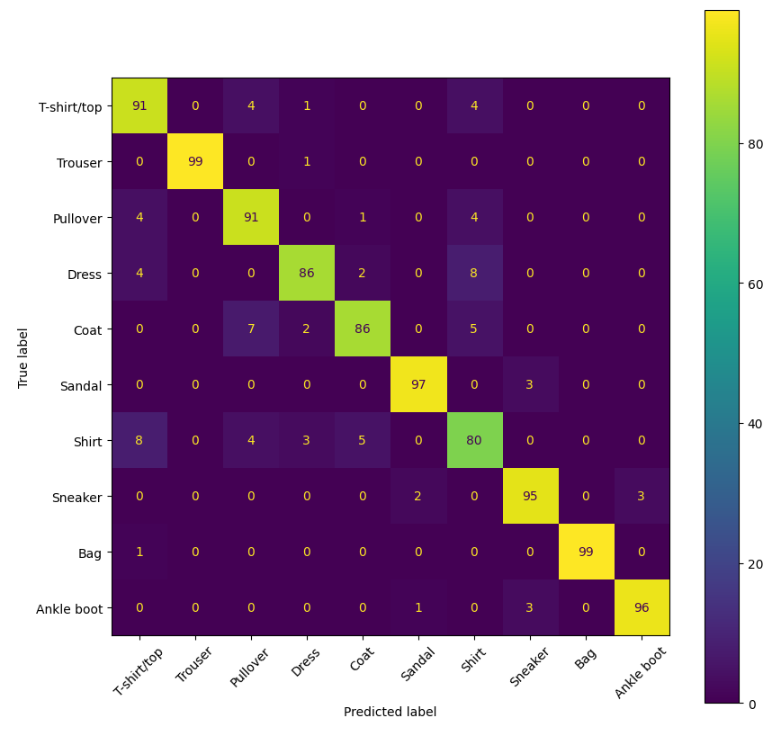
Swin과 마찬가지로 ViT에 비해 Shirt 클래스에 대한 recall을 높아졌다. 어쨋든 Swin이나 CvT나 vision transformer에 계층적 구조를 도입한 모델인데, 이것이 ViT에 2D local structure를 잘 포착할 수 있는 능력을 선사한 것 같다.
'책 > 파이토치 트랜스포머를 활용한 자연어 처리와 컴퓨터비전 심층학습' 카테고리의 다른 글
| 11 모델 배포 (2) 모델 경량화 (0) | 2024.03.15 |
|---|---|
| 11 모델 배포 (1) 모델 경량화 (0) | 2024.03.15 |
| 10 비전 트랜스포머 (2) Swin Transformer pytorch 실습 (0) | 2024.03.11 |
| 10 비전 트랜스포머 (1) ViT (0) | 2024.03.07 |
| 09 객체 탐지 (8) YOLO pytorch 실습 (0) | 2024.03.05 |


