양방향 RNN
앞에서 배운 Encoder에 초점을 맞춰보자. 그 구조는 다음과 같았다.

여기서 주목할 것은 모델이 왼쪽에서 오른쪽으로 처리한다는 것이다. 즉 '고양이'에 대한 은닉 상태를 만들어낼때는 '나', '는', '고양이' 까지 세 단어의 정보가 인코딩되어 들어간다. 여기에서 전체적인 균형을 생각하면 '고양이' 단어의 주변 정보를 균형 있게 담는 것이 좋을 것이다.
그래서 LSTM을 양방향으로 처리하는 방법을 생각할 수 있다.
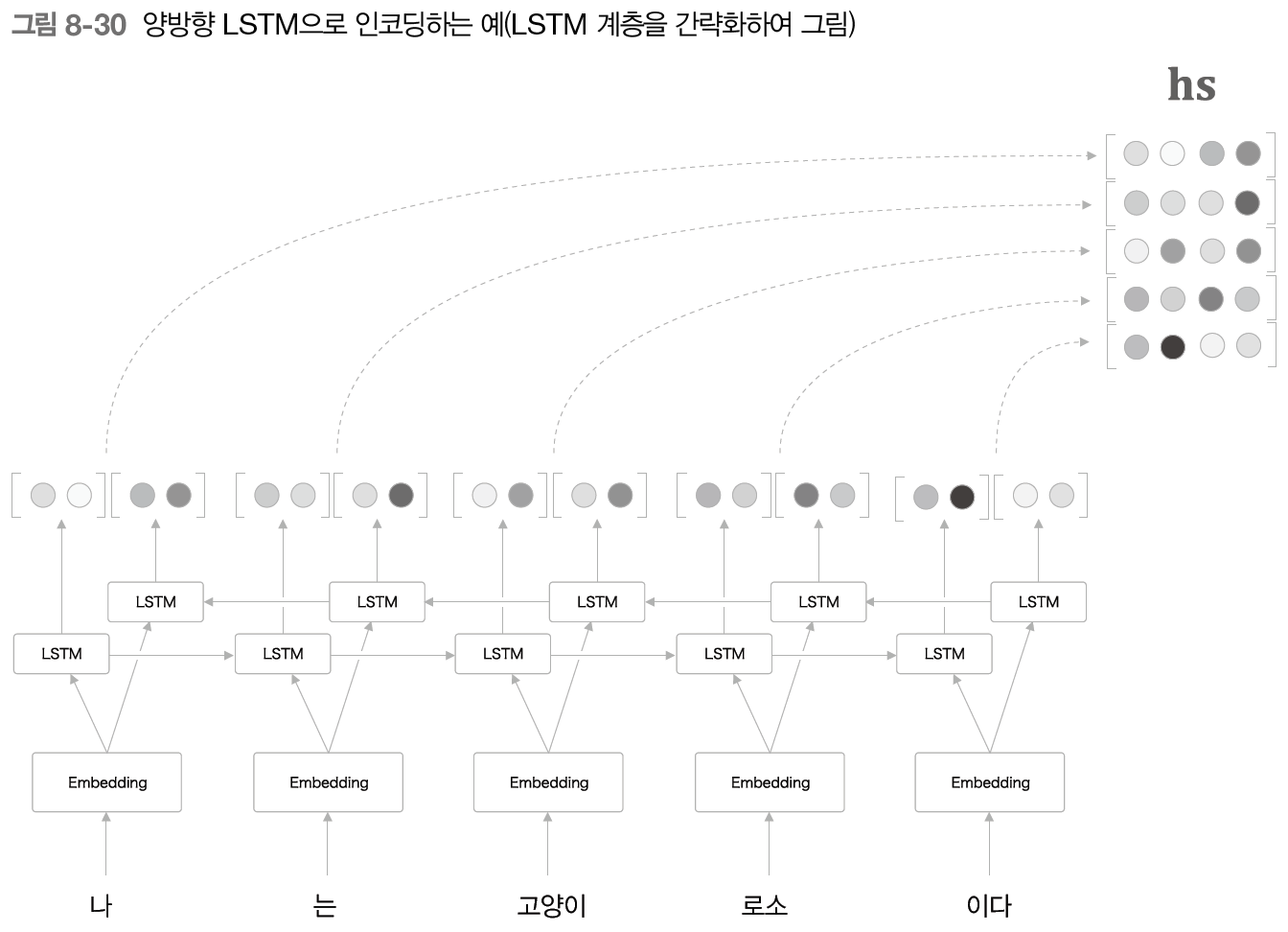
왼쪽에서 시작하는 TimeLSTM 계층과 오른쪽에서부터 시작하는 TimeLSTM 계층이 만들어내는 은닉 상태 벡터를 concat하여 정보를 균형있게 인코딩할 수 있다. 구현 할 때도 하나의 입력이 "abcd"이었다면 다른 것은 "dcba'로 순서를 바꿔 입력하면 된다.
class TimeBiLSTM:
def __init__(self, Wx1, Wh1, b1,
Wx2, Wh2, b2, stateful=False):
self.forward_lstm = TimeLSTM(Wx1, Wh1, b1, stateful)
self.backward_lstm = TimeLSTM(Wx2, Wh2, b2, stateful)
self.params = self.forward_lstm.params + self.backward_lstm.params
self.grads = self.forward_lstm.grads + self.backward_lstm.grads
def forward(self, xs):
o1 = self.forward_lstm.forward(xs)
o2 = self.backward_lstm.forward(xs[:, ::-1])
o2 = o2[:, ::-1]
out = np.concatenate((o1, o2), axis=2)
return out
def backward(self, dhs):
H = dhs.shape[2] // 2
do1 = dhs[:, :, :H]
do2 = dhs[:, :, H:]
dxs1 = self.forward_lstm.backward(do1)
do2 = do2[:, ::-1]
dxs2 = self.backward_lstm.backward(do2)
dxs2 = dxs2[:, ::-1]
dxs = dxs1 + dxs2
return dxs- 초기화에서 2가지 LSTM 계층을 선언한다.
- forward에서 각 backward_lstm은 행을 반전하여 입력하고 그렇게 얻은 은닉 상태를 다시 행을 반전하여 concat한다.
Attention 계층 사용 방법
우리는 Attention의 출력을 Affine 계층의 입력으로 사용하였지만 다음과 같이 다르게 사용할 수 있다.

이 예시에서는 Attention의 출력을 다음 시각의 LSTM 계층의 입력으로 사용하였다. 어떤 방식이 더 좋을지는 직접 해봐야한다.
seq2seq 심층화와 skip 연결
층을 깊게 쌓으면 표현력이 높은 모델을 만들 수 있는 것은 seq2seq 모델도 다르지 않다. 한 가지 예의 구조를 보자.

Encoder를 3층 LSTM으로 구성하고 Encoder로 부터 얻은 은닉 상태와 Decoder의 첫 번째 층의 LSTM의 은닉 상태를 Attention 계층에 입력하고 이렇게 얻은 맥락 벡터를 다른 여러 계층으로 전파한다.
층을 깊게 할 때 사용되는 중요한 기법 중 skip 연결이 있다.

이는 계층을 건너 뛰는 연결이고 skip 연결의 접속부에서는 2개의 출력이 더해진다. 이것의 장점은 덧셈 노드는 역전파시 기울기를 그대로 흘려보내기 때문에 층이 깊어져도 기울기가 소실하고 폭발되지 않고 전파되어 좋은 학습을 기대할 수 있다.
'책 > 밑바닥부터 시작하는 딥러닝 2' 카테고리의 다른 글
| 8장 어텐션 (1) (0) | 2023.11.03 |
|---|---|
| 7장 RNN을 사용한 문장 생성 (2) (0) | 2023.11.02 |
| 7장 RNN을 사용한 문장 생성 (1) (0) | 2023.11.01 |
| 6장 게이트가 추가된 RNN (2) (0) | 2023.10.31 |
| 6장 게이트가 추가된 RNN (1) (0) | 2023.10.27 |



