Photo-Realistic Single Image Super Resolution Using a Generative Adversarial Network
CVPR 2017
0.background
PSNR
Peak Signal-to-Noise Ratio의 약자로, 영상 및 음향 등 신호처리 분야에서 사용되는 평가지표이다. PSNR은 원본 신호와 압축된 또는 왜곡된 신호 간의 품질을 비교하는 데 사용된다. 수식은 다음과 같다.
PSNR=10log10(MAX2MSE)
MAX는 픽셀이나 샘플 값의 최대 가능 값이다. 예를 들어, 8비트 영상의 경우 MAX는 255이다. PSNR은 dB로 표시되며, 높은 PSNR 값은 더 좋은 품질을 나타낸다. 예를 들어, 30dB 이상인 경우, 거의 인간의 눈 또는 귀에서 구별할 수 없는 품질 손실로 간주된다.
SSIM
Structural Similarity Index Measure의 약자로 영상처리 분야에서 사용되는 또 다른 품질 평가 지표이다. PSNR과 달리 SSIM은 인간의 시각 시스템의 특성을 모델링하여 이미지 간의 구조적 유사성을 고려한다.
SSIM은 두 이미지가 얼마나 비슷한지를 나타내는 값이며, 0과 1사이의 값으로 표현된다. 1에 가까운 값이 두 이미지가 매우 유사하다는 것을 나타낸다.
SSIM은 밝기 유사도(l(x,y)), 대비 유사도(c(x,y)) , 구조 유사도(s(x,y)) 를 기반으로 계산된다.
SSIM(x,y)=[l(x,y)]α⋅[s(x,y)]β⋅[c(x,y)]γ
l(x,y)=2μxμy+C1μ2x+μ2y+C1
c(x,y)=2σxσy+C2σ2x+σ2y+C2
s(x,y)=σxy+C3σxσy+C3
- C1=(k1L)2, C2=(k2L)2, C3=C2/2
- L은 PSNR의 MAX와 동일하다.
- k1=0.01, k2=0.03이 default이다.
- α=β=γ=1이 default 값인데, 가중치를 조정하여 사용할 수 있다.
1. Introduction
일반적인 supervised SR 알고리즘의 최적화 대상은 복구된 HR 이미지와 실제 이미지 사이의 MSE를 최소화 하는 것이다. MSE를 최소화면 PSNR도 최대화되기 때문에 SR 알고리즘을 평가하고 비교하는 데 사용되는 일반적인 측정 기준이다.
그러나 MSE나 PSNR은 픽셀 단위의 이미지 차이를 기반으로 정의되기 때문에 high texture detail에는 제한적이다.

Figure 2를 보면 SRResNet의 PSNR과 SSIM 모두 제일 높지만, SRGAN의 결과가 시각적인 texture detail이 더 뛰어남을 알 수 있다.
따라서 저자들은 이러한 문제점을 극복하기 위해 VGG의 특징 맵을 이용한 새로운 지각적 손실을 정의하고, 이에 최적화된 ResNet과 skip connection을 사용하는 SRGAN을 제안한다.
2. Method
2.1 네트워크 구조
생성자 G는 ILR을 입력 받아 ISR을 생성해 판별자를 속이는 것을 목표로 학습된다. 그리고 판별자 D는 ISR과 IHR을 구분하도록 학습된다.
생성자 네트워크 구조는 다음과 같다.
생성자의 핵심은 B개의 Residual block이다. 각 블록은 k3n64s1 Conv 레이어, BN, ParametricReLU로 이루어져 있다. 그리고 입력 이미지의 해상도를 증가시키기 위해 학습된 2개의 sub-pixel convolution layer을 사용했다고 한다.
sub-pixel convolution layer은 업샘플링과 같은 작업에 사용되는 합성곱 연산으로 다음과 같은 주요 단계로 구성된다.
- 입력 분할: 입력 이미지를 여러 개의 작은 패치로 분할한다.
- 컨볼루션 수행: 각 패치에 대해 합성곱 연산을 수행한다.
- 픽셀 재구성: 각 패치의 특성 맵을 조합하여 고해상도 이미지의 픽셀 값을 재구성한다.
마지막 레이어에서는 3개의 채널을 사용하여 3채널 이미지로 복원한다.
판별자 네트워크 구조는 다음과 같다.
LeakyReLU(α=0.2)를 사용하였고, max-pooling은 이미지 크기를 줄이므로 사용하지 않는다. 3x3 kernel을 사용하는 conv layer 8개로 구성되어 있는데 채널 수는 VGG 처럼 64부터 512까지 증가한다.
이후 dense layer 2개와 이진 분류를 위한 sigmoid가 있다.
2.2 Perceptual loss
content loss와 adversarial loss로 구성되어 있다.
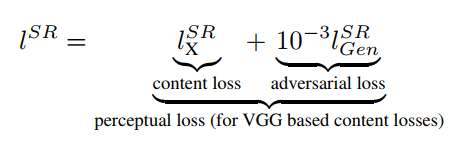
먼저 content loss는 다음과 같이 정의된다. 저자들은 이를 VGG loss라고 부르며, 사전 학습된 VGG19 네트워크를 이용한다.
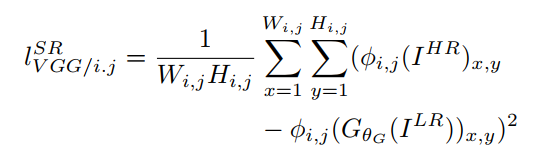
- ϕi,j : i번 째 max-pooling layer 이전 j번 째 conv layer 후 얻은 특징 맵
- Wi,j, Hi,j 위에서 얻은 특징 맵의 차원
간단하게 설명하면 위 수식은 생성자가 만들어낸 이미지와 reference 이미지를 각각 VGG에서 얻은 feature map에 통과시킨 후 서로의 유클리드 거리를 의미한다.
다음으로 adversarial loss이다.
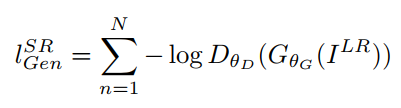
summation 옆의 식은 생성자가 생성한 이미지를 판별자가 진짜라고 판단할 확률을 의미한다.
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] HRNet - Human Pose Estimation (0) | 2024.05.31 |
|---|---|
| [논문 리뷰] Swin Transformer V2 (0) | 2024.05.02 |
| [논문 리뷰] Sharpness-Aware Minimization for Efficiently Improving Generalization (0) | 2024.04.21 |
| [논문 리뷰] Self-training with Noisy Student improves ImageNet classification (0) | 2024.04.20 |
| [논문 리뷰] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2024.04.19 |



