Swin Transformer V2: Scaling Up Capacity and Resolution
CVPR 2022
저자들은 large scale vision model의 훈련과 응용에서 세 가지 주요 문제점을 발견했다고 한다.
- 훈련 불안정성
- pre-training과 fine-tuning 간 해상도 차이
- 레이블된 데이터를 많이 필요로 하는 문제
이런 문제를 해결하기 위해 저자들이 제안한 기술은 다음과 같다.
- 훈련 안정성을 향상시키기 위한 consine attention과 결합된 residual-post-norm
- 저해상도 이미지를 사용하여 사전 훈련된 모델을 고해상도 입력을 사용하는 downstream으로 효과적으로 이전하는 log-spaced continuous position bias
- 광범위한 레이블이 필요 없도록 self-supervised 훈련 방법인 SimMIM
문제점은 아니지만 관련 연구에서 저자들이 언급한 내용인데, CNN 구조의 귀납적 편향(inductive bias)으로 인해 CNN 기반의 vision model의 크기를 키우더라도 performance가 크게 증게하지 않는다고 한다. 모델의 크기를 키우고 이를 성공적으로 훈련한 뒤 성능 향상으로까지 3박자 맞아 떨어져야 하는 이유는 인간 수준의 few-shot learning을 가능하게 하기 위함이다. NLP 모델들은 이 부분에 대해서 꽤나 성공적이지만, vision model들은 조금 뒤쳐진다고 한다.
1. Post normalization
Swin Transformer 뿐만 아니라 대부분의 transformer 기반 vision model들은 vanilla ViT를 따라 pre-normalization을 수행하였다.

위 그림처럼 layer normalization을 MSA, MLP 모듈의 앞쪽에 적용한 것이 pre-normalization이다. 이로 인해 block의 출력 활성화 값이 바로 main branch로 병합되기에 층이 깊어질 수록 활성화 크기가 점점 커진다고 지적하였다.
Post normalization은 다음 그림의 V2에서 MSA, MLP 모듈 뒤쪽에 LN을 적용한 것이다.

아래 그림은 4가지 scale의 original Swin Transformer의 깊이별 활성화 값의 분산을 나타낸다.
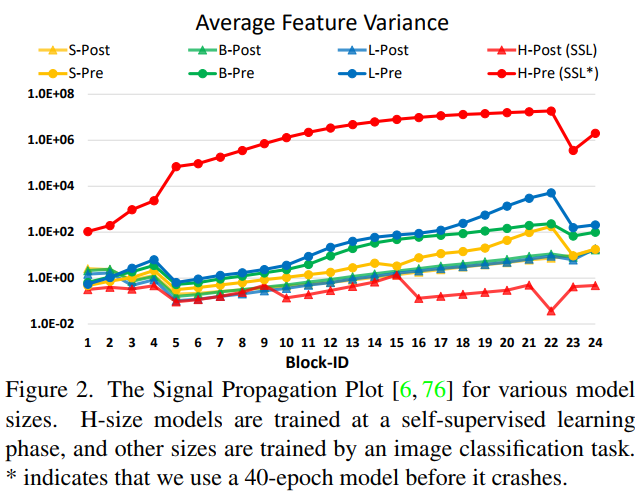
-Pre는 -Post는 각각 pre-normalization과 post normalization을 나타낸다. 이 효과는 H가 의미하는 huge 모델에서 특히나 두드러짐을 알 수 있다.
추가적으로 V2의 가장 큰 모델을 훈련할 때는 6개의 block마다 추가적인 layer normalization을 도입했다고 한다.
2. Scaled cosine attention
Post normalization을 적용한 뒤에 어텐션 맵의 값이 특정 픽셀 쌍에 대해 높게 나타나는 것을 발견했다. 이는 모델의 학습 및 일반화 능력에 영향을 주기 때문에 기존의 dot product 어텐션을 cosine 어텐션으로 바꾸었다.
Cosine 어텐션은 attention score를 코사인 유사도를 통해 계산하는 방법이다. 논문에서 사용한 scaled cosine attention은 여기에 학습 가능한 파라미터 $\tau$로 score를 나눠주기 때문이다. 수식은 다음과 같다.

$B_{ij}$는 편향으로 픽셀 i, j에 대한 relative position bias이다. 코사인 유사도 자체가 결과값이 -1과 1사이로 normalized되어 있기 때문에 좀 더 온건한 attention value를 얻을 수 있다고 한다.
저자들은 post norm과 scaled cosine attention을 사용해 훈련 불안정성을 문제를 해결하였다.
3. Log-spaced continuous position bias
기존의 relative position bias에 continuous relative position bias와 log-spaced coordinated를 적용한 것이다. 이 부분을 이해하기 위해서는 Swin Transformer 논문을 읽거나 이전 게시글을 참고하는 것이 좋다.
continuous relative position bias
기존의 relative position bias $B$는 사전 학습된 bias $\hat B$으로부터 parameterized된다. 그리고 $\hat B$은 다른 window size로 transferring될 때는 bi-cubic interpolation을 사용해 다른 크기의 $\hat B$을 초기화하는데 사용된다.
Continuous는 relative coordinates에 메타 네트워크를 적용하는 것이다. 메타 네트워크는 ReLU가 레이어 사이에 포함된 2-layer MLP이다. 수식은 다음과 같다.
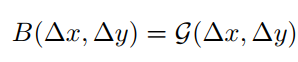
저 G같이 생긴 것이 메타 네트워크를 의미하고 $\Delta x, \Delta y $가 coordinates를 의미한다. 어렵게 생각할 것이 없는게 MLP를 사용해서 우리는 출력의 길이를 조절할 수 있다. 따라서 임의의 range를 가지는 relative coordinate 생성할 수 있다. 이로인해 다양한 window size로 transferring이 가능하다.
Log-spaced coordinates
우선 수식은 다음과 같다.
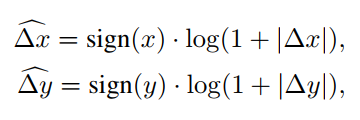
이 친구도 전혀 어렵지 않다. 예를 들어 8x8 window size에서 16x16 window size로 transferring 한다고 가정해보자. 기존에는 input coordinate가 각각 $[-7, 7] \times [-7, 7]$과 $[-15, 15] \times [-15, 15]$이다. 이에 대한 extrapolation ratio는 8/7이다.
여기에 위 수식을 적용하면 input coordinate는 $[-2.079, 2.079 ] \times [- 2.079 , 2.079 ]$과 $[-2.773, 2.773 ] \times [- 2.773 , 2.773 ]$으로 조정되며 extrapolation ratio는 0.33으로 약 4배 줄어든다.
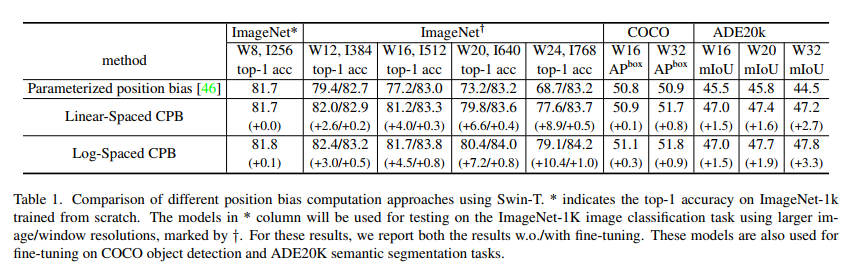
Log-Spaced CPB를 사용하여 사전 학습과 fine-tuning간의 해상도 차이로 인한 성능 저하를 극복할 수 있음을 다음 table에서 확인할 수 있다.
4. Self-Supervised Pre-traning
Large 모델을 훈련시키기 위해 일반적으로 JFT-3B와 같이 엄청 많은 labelled data가 필요하다. 저자들은 SimMIM을 사용하여 JFT-3B의 1/40에 해당하는 7천만개의 labelled data만 가지고 주요 비전 벤치마크에서 SOTA를 달성했다.
SimMIM은 SimMIM: A Simple Framework for masked Image Modeling에서 제안한 방법으로 여기서는 간단히 4가지 주요 구성 요소를 설명한다.
- 이미지 패치에 랜덤 마스킹을 적용한다. BERT의 마스킹과 비슷하다고 생각하면 된다.
- 마스킹된 이미지를 입력으로 받아 이미지 표현을 추출한다. Transformer 기반 인코더나 CNN 기반 인코더를 사용할 수 있다.
- 인코더에서 추출한 이미지 표현을 기반으로 마스킹된 영역의 original 픽셀의 RGB 값을 예측한다.
- 예측과 original의 차이를 계산하여 학습 과정을 이끌어주는데 일반적으로 L1 Loss를 손실 함수로 사용한다.
5. Model Configuration
| T | S | B | L | H | G | |
| C | 96 | 96 | 128 | 192 | 352 | 512 |
| block | {2, 2, 6, 2} | {2, 2, 18, 2} | {2, 2, 18, 2} | {2, 2, 18, 2} | {2, 2, 18, 2} | {2, 2, 42, 4} |
- C는 첫 번째 스테이지의 linear embedding dimension을 의미한다.
- H, G는 각각 658M, 3B의 매개변수를 가진다.
마지막으로 내가 이 모델을 scratch부터 학습할 일은 아마 없을 것이기 때문에 fine-tuning detail만 정리하고 글을 마무리 지어볼까 한다.
- optimizer: AdamW
- scheduler: cosine decay
- learning rate: 4e-5
- weight decay: 1e-8
- augmentation: RandAugment, Mixup, Cutmix, random erasing, stochastic depth (ratio=0.2)
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] HRNet - Human Pose Estimation (0) | 2024.05.31 |
|---|---|
| [논문 리뷰] SRGAN (0) | 2024.04.23 |
| [논문 리뷰] Sharpness-Aware Minimization for Efficiently Improving Generalization (0) | 2024.04.21 |
| [논문 리뷰] Self-training with Noisy Student improves ImageNet classification (0) | 2024.04.20 |
| [논문 리뷰] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2024.04.19 |



