XGBoost는 기본적으로 GBM의 철학을 따라가되 어떻게하면 더 빠르고 대용량의 데이터에 대해서도 처리가 가능한지에 대한 고민에서 출발한 알고리즘이다. 이를 위해 근사 알고리즘을 사용하여 약간의 성능 저하가 있을 수도 있지만 대용량의 데이터를 다룰 수 있는 병렬처리 기법 등을 통해서 이러한 단점을 보완한다. 이 포스팅에서는 하드웨어적인 부분은 다루지 않고 꼭 이해해야할 알고리즘 관련한 부분만 다룬다.
Split Finding Algorithm
Basic exact greedy algorithm
의사결정나무에서 split을 위해 사용하는 알고리즘이다.
- 장점
- 모든 가능한 split point를 다 찾아보기 때문에 항상 최적의 split point를 찾는다.
- 단점
- 데이터가 너무 커서 메모리에 다 들어가지 않을 경우 효율적으로 사용할 수 없다.
- 분산 환경에서 불가능하다.
Approximate algorithm
- 정렬된 데이터의 분포를 보고 변수를 여러개의 bucket으로 그룹지어 분산한다.
- 그리고 bucket마다 split point를 찾는다.

- 예시로 40개의 데이터가 정렬되어 있고 10개의 bucket으로 나뉘어져 있다.
- 이런 경우에 exact greedy 알고리즘은 39번의 split point에 대해서 계산한다.
- 반면에 근사 알고리즘은 각각의 bucket에서 3번씩 총 30번만 gradient를 계산한다.
- 또한 각각 bucket마다 gradient를 계산하는 것을 병렬처리가 가능하기 때문에 시간이 훨씬 단축된다.
주의 해야 할 점은 위의 예시의 경우엔 두 가지 알고리즘의 best split point가 같겠지만 근사 알고리즘의 최적의 split point가 찾아지지 않을 수도 있다.
분산 방법은 다음과 같이 2가지 방법이 있다.

- Global variant 같은 경우에는 처음 만들어진 bucket의 구분을 그대로 사용한다.

- local variant는 각각의 child node들에 대해서도 bucket 사이즈를 유지하여 분할한다.
- 처음에 10개 였기 때문에 자식 노드들도 10개의 bucket을 가진다.

- bucket size를 결정하는 하이퍼파라미터는 $\epsilon$이고 $1/ \epsilon$개의 bucket을 가진다.
- global이나 local의 성능에는 큰 차이가 없지만 global을 사용할 경우 $\epsilon$ 값을 작게하여 더 많은 bucket으로 분할하여야 한다.
Sparsity-Aware Split Finding
실제 문제를 다룰 때 데이터가 sparse한 경우가 많이 있다. 주요 요인으로는 결측치가 있다거나, 값이 0이라거나, 원-핫 인코딩의 영향이 있다.
이를 해결하기 위해 학습 과정에서 이러한 데이터들에 대한 default direction을 정하여서 해당 방향으로 데이터를 보내버린다.
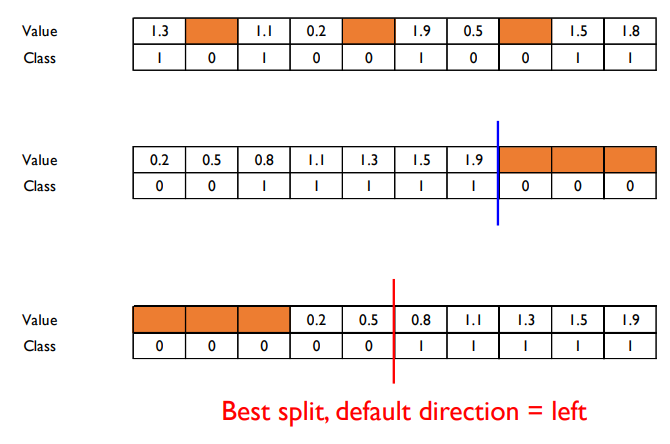
- 위와 같이 missing value들을 다 오른쪽이나 왼쪽으로 보낸 뒤 각각 score를 계산하여 default direction을 정한다.
- 그런 다음 새로운 데이터가 들어왔을 때 missing value가 있다면 정해진 방향으로 보내버린다. 즉 left child node로 보낸다.
'Machine Learning > Business Analytics 2' 카테고리의 다른 글
| 4-9 : Ensemble Learning - CatBoost (0) | 2024.01.03 |
|---|---|
| 4-8 : Ensemble Learning - Light GBM (0) | 2023.12.29 |
| 4-6 : Ensemble Learning - Gradient Boosting Machine (GBM) (0) | 2023.12.28 |
| 4-5 : Ensemble Learning - Adaptive Boosting (AdaBoost) (0) | 2023.12.18 |
| 4-4 : Ensemble Learning - Random Forest (0) | 2023.12.18 |



