Boosting : AdaBoost
Idea
- strong model vs weak model
- random guessing보다 약간 더 좋은 성능을 가진 weak model을 정확한 strong model로 향상(boosting) 시킬 수 있다.
- boosting 과정을 간단히 살펴 보자면 다음과 같다.
- 학습 데이터 준비
- weak model 생성
- 이전 weak model 어려워한 케이스들에 대해 학습 데이터의 샘플들의 가중치를 재조정
- 가중치가 재조정된 학습 데이터로 다음 weak model 생성
- 반복
- 여러 번 반복으로 만들어진 weak model들을 결합하여 하나의 strong model을 만듬
정리해보자면
- 각 라운드마다 새로운 모델을 훈련하여 순차적(sequential)으로 모델을 훈련한다.
- 각 라운드가 끝나면 잘못 분류된 예제가 식별되고 새 훈련 세트에서 강조가 증가되어 다음 라운드로 피드백된다.
- 이전 모델에서 발생한 큰 오류는 후속 모델에서 보완 가능하다.
Algorithm

위는 pseudocode로써 한 줄씩 이해해보자.
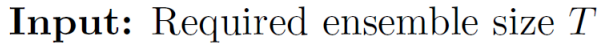
- 우선 individual learner의 개수 T를 지정해줘야 한다. 일반적으로 sklearn 같은 경우 n_estimator이다.
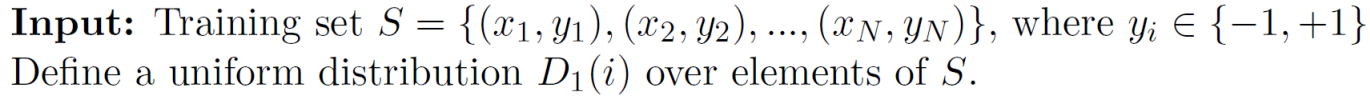
- 여기서는 이해를 돕기 위해 이진 분류를 예로 들었다.
- 보통 이진 분류의 label은 (0, 1)인데 여기서는 뒤의 수식을 위해 (-1, 1)로 사용한다.
- $D_1(i)$는 첫 번째 데이터셋의 sample i가 선택될 확률을 의미한다.
- 여기서 Define a uniform distribution이라고 표현한 것은 처음에는 모든 데이터에게 동등하게 선택될 확률을 부여한다는 뜻이다.
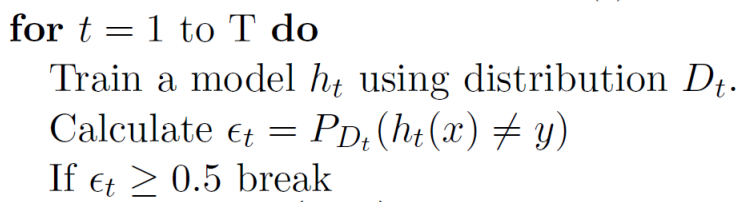
- 1번 째 모델부터 T번 째 모델까지 순차적으로 학습한다.
- 여기서 사용하는 모델 $h_t$는 stump tree이다. stump tree란 분류선을 축에 수직으로 딱 한 번만 그어서 분류하는 tree이다.
- $\epsilon_t$를 계산하는데 이는 잘못 분류한 비율이다.
- 잘못 분류한 비율이 0.5보다 크거나 같으면 random guessing보다 못한 성능이므로 다음으로 넘어간다.
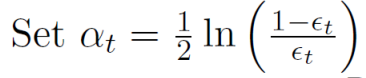
가중치 $\alpha_t$를 계산한다. $\epsilon_t$가 0.5에 근접한 값 즉, 모델의 성능이 떨어지면 가중치는 0이고, $\epsilon_t$가 0.0에 근접한 값 즉, 모델의 성능이 좋으면 가중치는 매우 큰 숫자가 된다.
위에서 보았듯이 여기서 사용하는 모델은 stump tree를 사용하기 때문에 $\epsilon_t$가 0.0에 근접할 수는 없다.
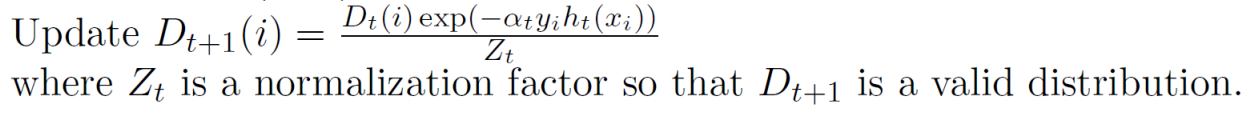
- 다음 모델을 위한 데이터셋의 분포를 업데이트 한다.
- $Z_t$는 정규화를 위한 factor로써 잠깐 무시하고 분자의 exponential 안쪽만 살펴보자.
- $y_i$는 정답이고 $h_t$는 예측이다. 아까 위에서 우리는 라벨을 (0, 1)이 아닌 (-1, 1)을 사용하기로 했었다. 그래서 정답과 에측이 같다면 둘의 곱은 1이되고, 다르다면 -1이 된다.
- $\alpha_t$는 항상 양수이기 때문에 정답과 예측이 같다면 exponential 값은 작아진다. 반대로 정답과 예측이 다르다면 exponential 값은 커진다.
- 즉, 잘못 예측한 샘플에 대해서 더 큰 가중치를 부여하는 것이다.
Illustrative example
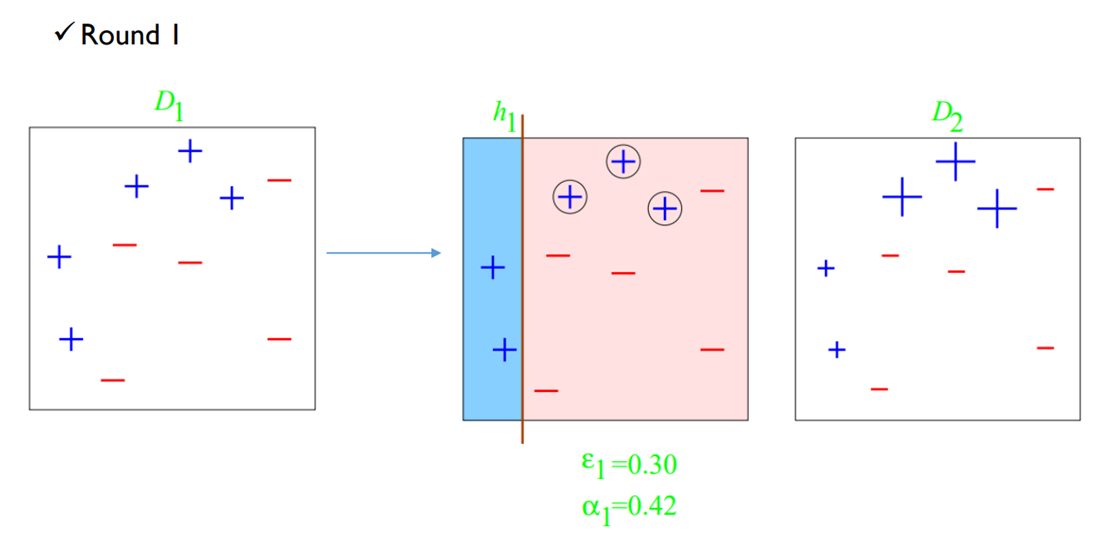
$D_1$로 부터 모델 $h_1$을 학습하고 잘못 분류된 샘플들에 대해 가중치를 부여한 새로운 확률 분포 $D_2$를 업데이트 한다. $D_2$를 보면 정분류한 샘플들은 크기를 작게 표현하고 오분류한 샘플들은 크기를 크게 표현함으로써 서로 다른 확률을 갖고 있음을 표현하였다.
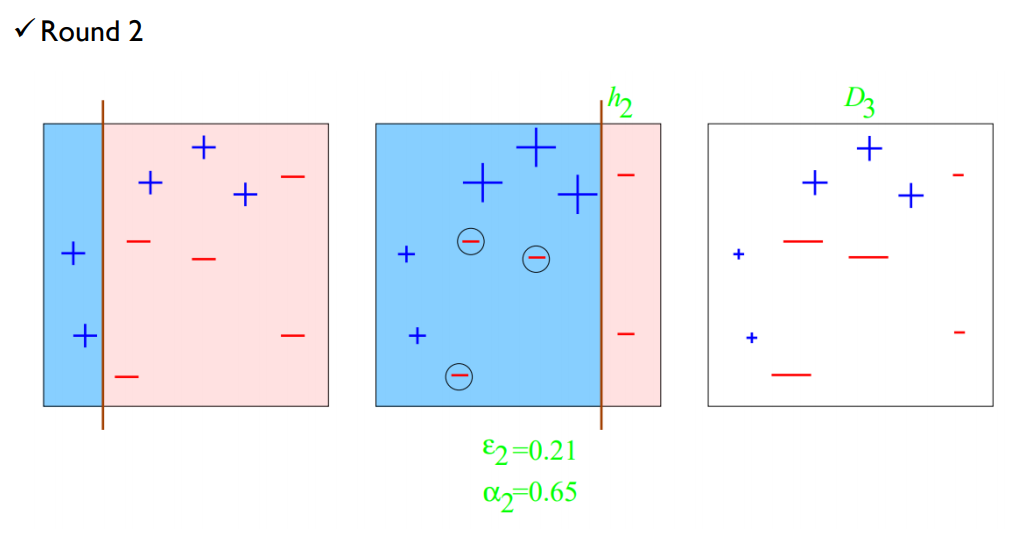
새로 학습된 $h_2$를 보면 이전에 오분류된 샘플들을 더 잘 분류하는 쪽으로 학습되었다. 마찬가지로 $D_3$을 업데이트 한다.
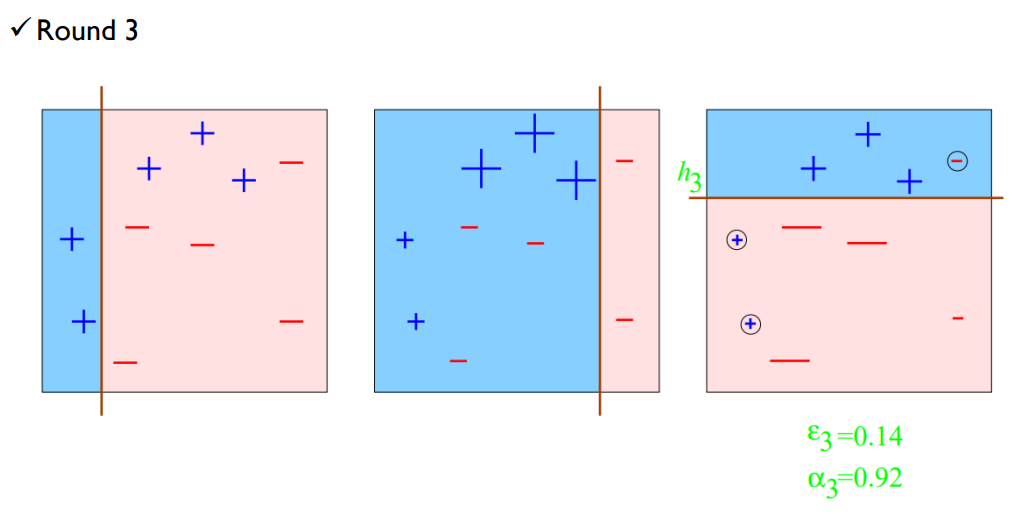

3개의 개별 tree를 통해서 완벽히 분류해내는 단일 모델을 만들었다.
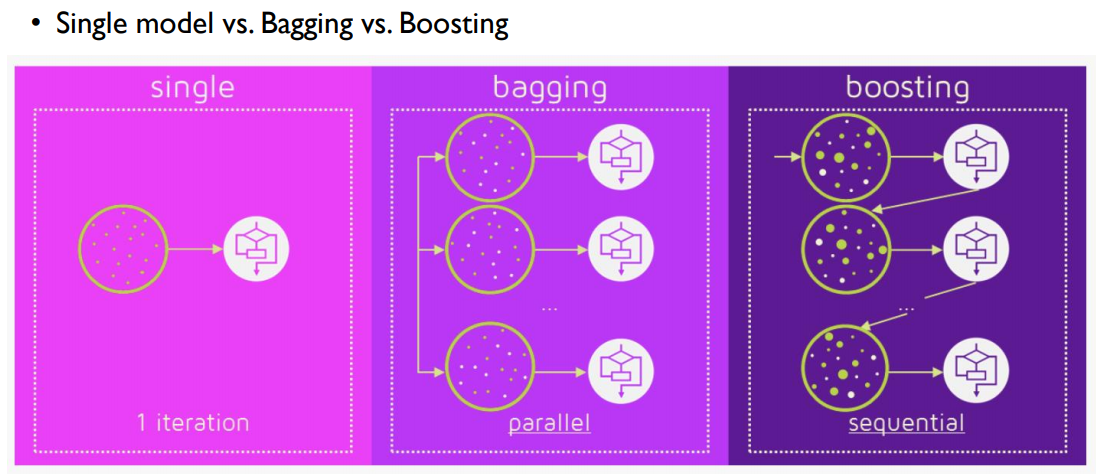
bagging의 경우 uniform ditribution을 가지고 병렬적으로 학습을 하고 boosting은 다른 분포를 가지고 순차적으로 학습을 한다. 그래서 bagging의 경우가 학습 시간이 더 짧을 것 같지만 실제로는 boosting의 총 학습 시간이 더 적은 경우가 많다고 한다. bagging의 경우 단일 모델 하나를 학습시키는데 오래 걸리는 경우가 많아서 그렇다고 한다.
'Machine Learning > Business Analytics 2' 카테고리의 다른 글
| 4-7 : Ensemble Learning - XGBoost (0) | 2023.12.29 |
|---|---|
| 4-6 : Ensemble Learning - Gradient Boosting Machine (GBM) (0) | 2023.12.28 |
| 4-4 : Ensemble Learning - Random Forest (0) | 2023.12.18 |
| 4-3 : Ensemble Learning - Bagging (0) | 2023.12.11 |
| 4-2 : Ensemble Learning - Bias-Variance Decomposition (0) | 2023.12.11 |



