언어 모델
언어 모델은 단어 나열(시퀀스)에 확률을 부여한다. 그 시퀀스가 일어날 가능성이 어느정도인지를 확률로 평가하는 것이다.
언어 모델을 수식으로 이해해보자. $w_1$, ..., $w_m$이라는 m개 단어로 된 문장이 있고, 이때 단어가 $w_1$, ..., $w_m$이라는 순서로 출현할 확률을 $P(w_1, ..., w_m)$으로 나타낸다. 이 확률은 여러 사건이 동시에 일어날 확률이므로 동시 확률이라 한다.
이 동시 확률을 사후 확률(조건부 확률)을 사용하여 다음과 같이 분해할 수 있다.

식 5.4의 결과는 확률의 곱셈정리로부터 유도할 수 있다.

이 곱셈 정리를 사용하면 m개 단어의 동시확률을 사후 확률로 나타낼 수 있다.


이를 반복하여 식 5.4를 유도한다. 식 5.4를 보면 알 수 있는 것이 타깃 단어보다 왼쪽에 있는 모든 단어를 맥락으로 했을 때의 확률이라는 것이다.

CBOW 모델을 언어 모델로?
CBOW 모델을 언어 모델에 적용하려면 다음과 같이 맥락의 크기를 특정 값으로 한정하여 근사적으로 나타낼 수 있다. 여기서는 맥락을 왼쪽 2개의 단어로 한정한다.

이 맥락의 길이 (윈도우 크기)를 늘릴 수 있지만 어쨋든 특정 길이로 고정된다. 맥락보다 더 왼쪽에 있는 단어의 정보는 무시된다는 뜻이다. 또한 CBOW 모델에서는 맥락 안의 단어 순서가 무시된다는 한계가 있다. 왜 무시가 되냐면 앞 장으로 생각해보면 맥락으로 부터 은닉층 $h_1$,... $h_m$을 구한뒤에 이를 모두 합하였기 때문이다.

순서를 무시하지 않기 위해서는 그림의 오른쪽 처럼 은닉층을 concat하는 방식을 생각할 수 있다. 그러나 이는 맥락의 크기에 비례해 가중치 매개변수도 늘어나는 단점이 있다.
이 문제를 해결하는 방법이 RNN을 사용하는 것이다. RNN을 사용하면 맥락이 아무리 길더라도 그 맥락의 정보를 기억하는 메커니즘을 갖추고 있다.
RNN이란
순환하는 신경망
데이터가 신경망에서 순환하기 위해서는 닫힌 경로가 필요하다. 간단한 RNN 계층은 다음과 같이 나타낸다.

t는 time step을 의미한다. 시계열 데이터 $(x_0, x_1, ..., x_t, ...)$가 RNN 계층에 입력되고 그 입력에 대응하여 $(h_0, h_1, ..., h_t, ...)$을 출력한다.
또한 각 time step에 입력되는 $x_t$는 벡터라고 가정한다. 문장을 다루는 경우 각 단어의 분산 표현이 될 수 있고, 이 분산 표현들이 time step마다 순서대로 하나씩 RNN 계층에 입력되는 것이다.
순환 구조 펼치기

time step 마다 RNN 계층의 입출력을 위와 같이 나타낼 수 있다. 실제로는 RNN 계층 하나만 존재한다. 여기서 알 수 있듯이 RNN은 이전 타입 스텝의 출력도 입력으로 받는다. 이를 수식으로 나타내면 다음과 같다.
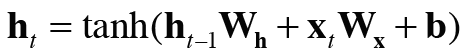
$h_t$는 은닉 상태(hidden state)라고 부른다.
BPTT
Backpropagation Through Time으로 '시간 방향으로 펼친 신경망의 오차역전파법'이다.

BPTT를 수행할 때 시간의 크기가 커질 수록 소비하는 컴퓨팅 자원이 증가하고, 역전파 시의 기울기가 불안정해지는 문제가 있다.
Truncated BPTT
그래서 큰 시계열 데이터를 취급할 때는 시간축 방향으로 너무 길어진 신경망을 적당한 지점에서 잘라내어 작은 신경망 여러개로 만든 뒤 오차역전파를 수행한다.
제대로 구현하려면 forward의 흐름은 유지하고 backward의 흐름만 끊어야 한다. 그림으로 알아보자
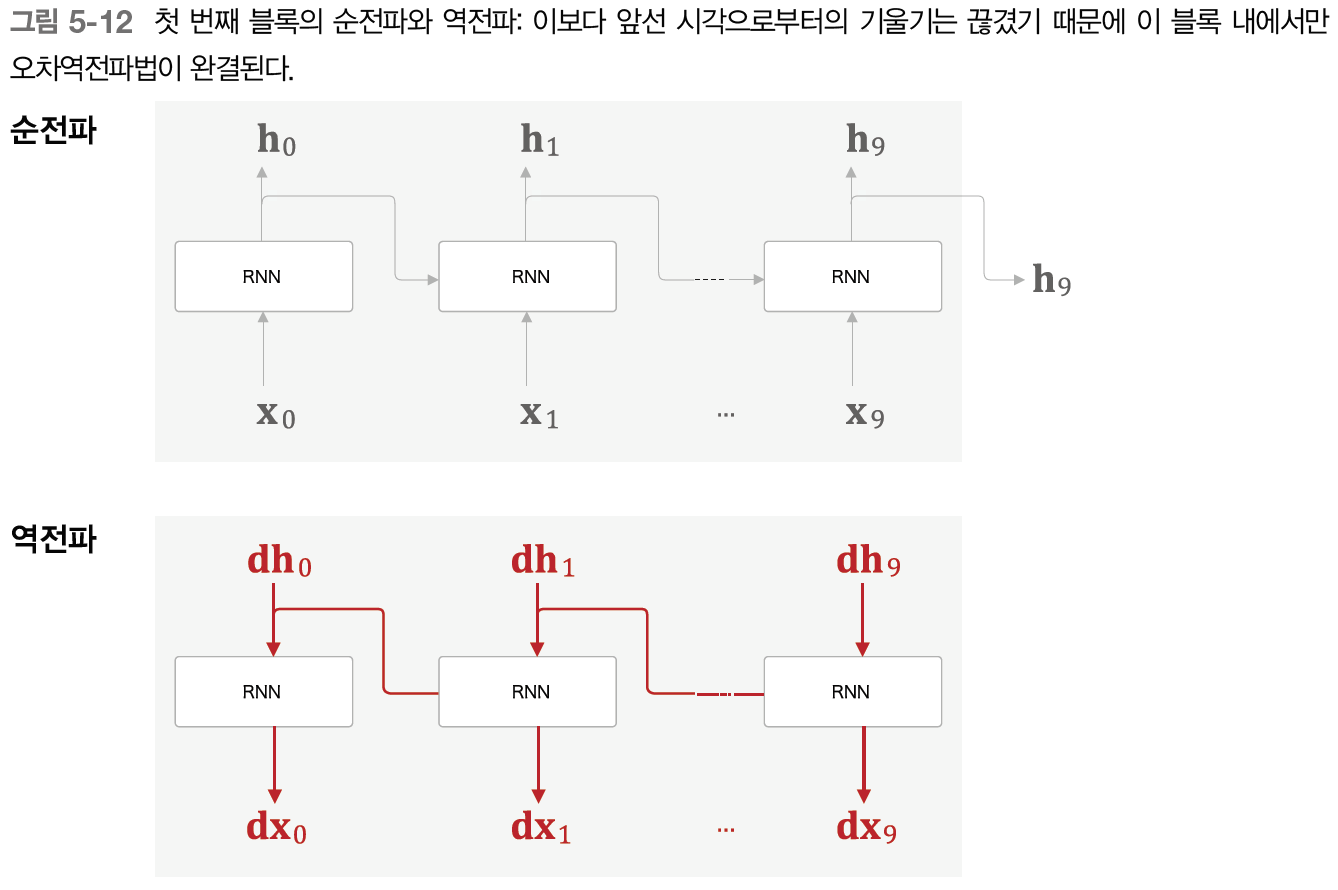
첫 번쨰 블록의 마지막 은닉 상태를 다음 블록의 입력으로 사용하여 forward가 끊이지 않게 할 수 있다.

Truncated BPTT의 미니배치 학습
예를 들어 길이가 1000인 시계열 데이터에 대해서 시각의 길이를 10개 단위로 잘라 학습하는 방법을 생각해보자. 이때 미니배치의 크기가 2라면 학습 처리 순서는 다음과 같아진다.
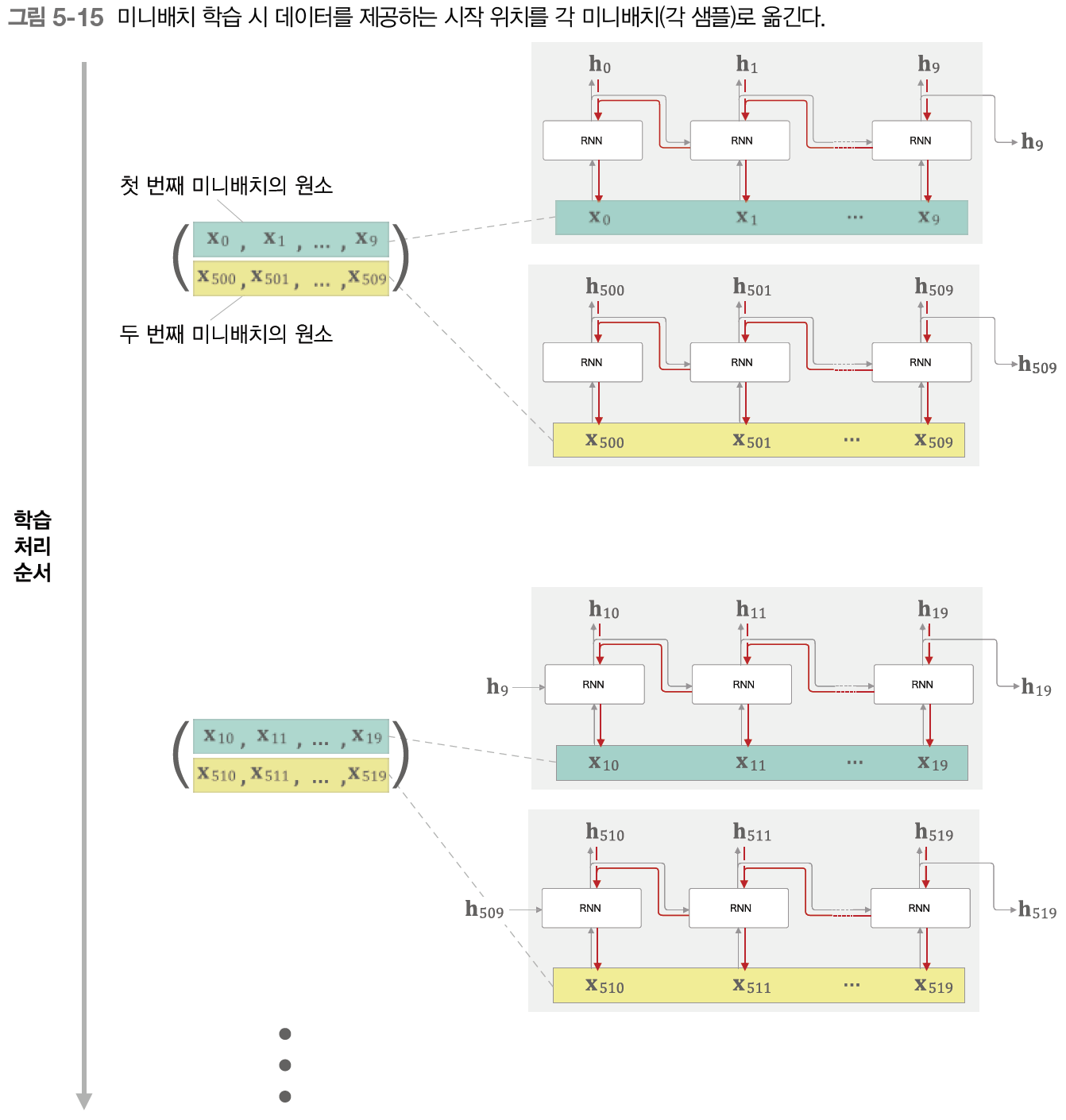
즉, 각 미니배치의 두 번째 인덱스에 해당하는 데이터는 첫 번째 인덱스의 데이터보다 500 time step 만큼 이동해줘야 한다.
RNN 구현
다음과 같이 시간의 길이가 T로 고정된 계층을 구현하는 것이 목표이다. 이를 TimeRNN 이란 이름의 클래스로 구현한다. 먼저 RNN의 하나의 타임 스텝만 처리하는 클래스를 RNN이란 이름으로 구현하고 이를 이용해 T개 단계의 처리를 한꺼번에 수행하는 계층을 만들어 보자.
RNN 계층 구현
앞에서 보았듰이 RNN의 forward는 수식으로 다음과 같다.

미니배치를 고려한 행렬의 형상은 다음과 같다.

문장을 예로 들면 각 단어가 D차원의 분산 표현으로 표현된것이다.
class RNN:
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev):
Wx, Wh, b = self.params
t = np.dot(h_prev, Wh) + np.dot(x, Wx) + b
h_next = np.tanh(t)
self.cache = (x, h_prev, h_next)
return h_nextforward 부분은 위의 수식을 그대로 옮긴 것이다. backward는 다음 그림을 따라 수행한다.

참고로 $y=tanh(x)$의 $dy/dx = 1-tanh(x)^2 = 1-y^2$이다.
def backward(self, dh_next):
Wx, Wh, b = self.params
x, h_prev, h_next = self.cache
dt = dh_next * (1 - h_next**2) # tanh 노드의 역전파
# 편향의 gradient
db = np.sum(dt, axis=0)
# 은닉 상태 MatMul 노드
dWh = np.matmul(h_prev.T, dt)
dh_prev = np.matmul(dt, Wh.T)
# x MatMul 노드
dWx = np.matmul(x.T, dt)
dx = np.matmul(dt, Wx.T)
self.grads[0][...] = dWx
self.grads[1][...] = dWh
self.grads[2][...] = db
return dx, dh_prevTime RNN 계층 구현
class TimeRNN:
def __init__(self, Wx, Wh, b, stateful=False):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None
self.h, self.dh = None, None
self.stateful = stateful
def set_state(self, h):
self.h = h
def reset_state(self):
self.h = Nonestateful은 '상태가 있는'이란 뜻으로 True일 경우 TimeRNN 계층의 은닉 상태를 유지하고, False일 경우엔 은닉 상태를 영행렬로 초기화한다.
인스턴스 변수 h는 forward시 최종 은닉 상태를 저장하고, dh는 backward시 이전 블록의 마지막 은닉상태의 기울기를 저장한다.
def forward(self, xs):
Wx, Wh, b = self.params
N, T, D = xs.shape # N: 배치크기, T: 타임 스텝의 길이, D: 분산 표현의 차원
D, H = Wx.shape # H: 은닉 상태의 차원
self.layer = []
hs = np.empty((N, T, H), dtype='f')
# 은닉 상태 초기화
if not self.stateful or self.h is None:
self.h = np.zeros((N, H), dtype='f')
for t in range(T):
layer = RNN(*self.params)
self.h = layer.forward(xs[:, t, :], self.h)
hs[:, t, :] = self.h
self.layers.append(layer)
return hsbackward의 계산 그래프는 다음과 같다.

t번째 RNN 계층의 역전파를 주목하면 다음과 같다.

forward시 RNN 계층의 출력이 분기하기 때문에 역전파를 계산할 때는 $dh_t$와 $dh_{next}$ 합하여 계산한다.
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D, H = Wx.shape
dxs = np.empty((N, T, D), dtype='f')
dh = 0
grads = [0, 0, 0] # dWx, dWh, db
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh = layer.backward(dhs[:, t, :] + dh)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad # dWx, dWh, db
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
'책 > 밑바닥부터 시작하는 딥러닝 2' 카테고리의 다른 글
| 6장 게이트가 추가된 RNN (1) (0) | 2023.10.27 |
|---|---|
| 5장 RNN (2) (0) | 2023.09.27 |
| 4장 word2vec 속도 개선 (0) | 2023.09.26 |
| 3장 word2vec (0) | 2023.09.25 |
| 2장 자연어와 단어의 분산 표현 (0) | 2023.09.24 |



