매개변수 갱신
최적화(optimization) : 매개변수의 최적값을 찾는 문제
확률적 경사 하강법(SGD)
앞장에서 보았던 가장 간단한 방법
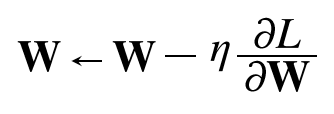
파이썬으로 구현해보자
class SGD:
"""확률적 경사 하강법 (Stochastic Gradient Descent)"""
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]초기화 때 learning rate을 받고 update 메서드에서 가중치 매개변수와, gradient가 저장된 딕셔너리를 받아 매개변수를 갱신한다.
SGD의 단점
손실함수의 그래프가 다음과 같은 모습이라고 생각해보자

이 함수에 대한 여러 지점에서의 기울기를 그려보면 다음과 같다.
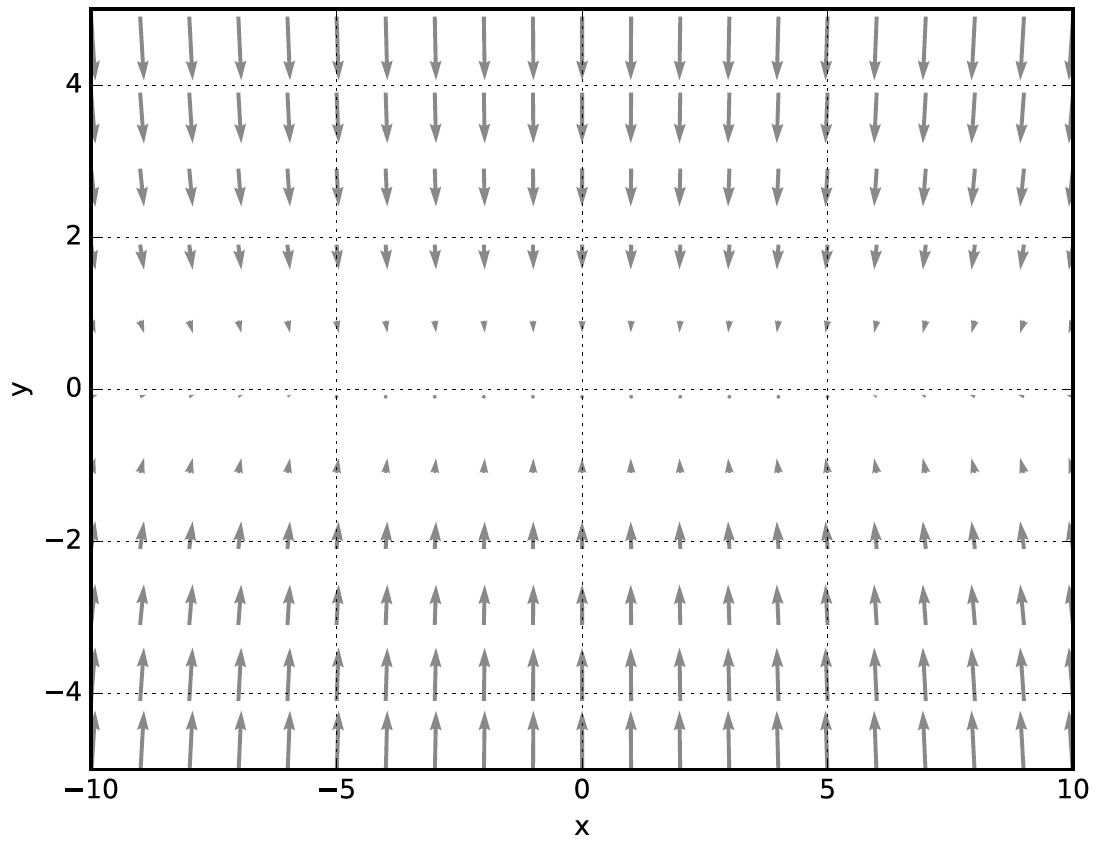
- y축 방향은 가파른데 x축 방향은 완만하다.
- 최솟값이 되는 장소는 (x, y) = (0, 0)인데 대부분이 이를 가리키고 있지 않다.
이 함수에 SGD를 적용해보자

- SGD의 단점은 비등방성 함수에서는 탐색 경로가 비효율적이다.
- 비등방성이란 방향에 따라 물체의 물리적 성질이 다른것이다. 여기서는 방향에 따라 함수의 기울기의 성질이 다르다고 이해하면 될 것 같다.
모멘텀


가중치 매개변수에 대한 손실함수의 gradient 뿐만 아니라 새로운 변수 $v$를 가지고도 갱신한다.
초기 v 값은 0이다. 따라서 맨 처음 갱신할 때는 SGD와 동일하게 작용한다. 그 다음부터는 $\alpha$(보통 0.9)만큼 이전 값을 기억해서 그 다음에 갱신할 때 gradient에 더해 적용하는 것이다.
어떻게 보면 관성이 좀 적용된 최적화라고 볼 수 있다.
코드로 구현해보자
class Momentum:
"""모멘텀 SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]별거 없다.
Nesterov 가속 경사
모멘텀의 변종으로 손실함수의 gradient를 계산할 때 $W$에 대해 계산하는 것이 아니라 모멘텀이 적용된 $W + v$에 대해 계산하는 것이고 다른 수식은 동일하다.
일반적으로 모멘텀 벡터가 올바른 방향을 가리킬 것이므로 이런 변경이 가능하다. 그래서 그 방향으로 좀더 나아가서 측정한 그레디언트를 사용하는 것이 약간 더 정확할 것이고 이러한 작은 개선이 쌓여 속도도 빨라진다.
구현은 다음과 같다.
class Nesterov:
"""Nesterov's Accelerated Gradient (http://arxiv.org/abs/1212.0901)"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] *= self.momentum
self.v[key] -= self.lr * grads[key]
params[key] += self.momentum * self.momentum * self.v[key]
params[key] -= (1 + self.momentum) * self.lr * grads[key]params[key]를 갱신하는 부분은 아마 해석적으로 gradient를 계산하면 저렇게 간소화 되지 않을까 하는 생각이 든다.
AdaGrad
learning rate decay가 적용된 옵티마이저이다. 개별 매개변수별로 adaptive 하게 학습률을 조정하여 저런 이름이 붙었다. 수식은 다음과 같다.


- $h$의 초기값은 0이다.
- ⨀은 element wise 곱이다.
- 아래 수식에 $1/\sqrt{h}$가 곱해지는 부분이 학습률 감소가 적용된 부분이다. 이 뜻은 h의 요소 중 큰 값에 해당하는 가중치는 더 큰 폭으로 학습률을 감소한다는 뜻이다.
구현은 다음과 같다.
class AdaGrad:
"""AdaGrad"""
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)AdaGrad가 마냥 좋기만 한 것은 아닌것이 과거의 기울기를 제곱하여 계속 더해가기 때문에 학습을 진행할수록 갱신 강도가 약해진다. 이를 개선한 것이 지수이동평균을 적용하여 과거의 기울기의 반영을 줄이는 기법인 RMSProp이다.
*지수이동평균
Exponential Moving Average or Exponential Weighted Moving Average라고 부른다. 오래된 데이터에 대한 가중치는 기하 급수적으로 감소하지만 0이 되지는 않는다.

exponential 이름이 붙은 이유는 수식에서 볼 수 있듯이 step이 지남에 따라 이전 데이터에 (1-α)가 계속 곱해지기 때문
RMSProp
class RMSprop:
"""RMSprop"""
def __init__(self, lr=0.01, decay_rate = 0.9):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)보통 감쇠율은 0.9로 설정한다.
Adam
Adaptive Moment Estimation을 의미하고 모멘텀 최적화와 RMSProp의 아이디어를 합친것이다. 즉, 모멘텀의 지수 감소 평균을 따르고 RMSProp처럼 이전 gradient 제곱의 지수 감소된 평균을 따른다.
class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key]) # 시간이 지날수록 과거의 가중치가 희미해짐
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key]) # 마찬가지로 과거의 가중치가 희미해짐
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)여기에 Nesterov가 적용된 Nadam도 있다.
'책 > 밑바닥부터 시작하는 딥러닝' 카테고리의 다른 글
| 7장 CNN (1) (0) | 2023.09.21 |
|---|---|
| 6장 학습 관련 기술들 (2) (0) | 2023.09.20 |
| 5장 오차역전파법 (2) (0) | 2023.09.19 |
| 5장 오차역전파법 (1) (0) | 2023.09.19 |
| 4장 신경망 학습 (2) (0) | 2023.09.14 |



