2019년 8월에 발행된 논문으로 코드 유사성 판단 경진대회 문제를 해결하기 위해 읽게 됐다. 해당 대회의 데이터는 C++로 작성된 두 쌍의 코드가 있고, 유사성을 1과 0으로 나타내는 label이 있다.
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
0. background
Siamese Network

Siamese network는 가중치를 공유하는 2개의 네트워크가 있고 각각의 네트워크에 input1, input2를 입력받은 뒤 embedding1, embedding2를 출력한다. 그런 다음 두 임베딩 벡터의 유사도를 측정하는 목적 함수(코사인 유사도, L1, L2, 맨해튼, 유클리디안 등)를 거쳐 목적에 맞는 작업을 수행한다.
Triplet Network

Triplet Network도 마찬가지로 3개의 네트워크가 가중치를 공유한다. 입력은 3개가 있는데, anchor는 기준이 되는 입력, positive는 anchor와 의미적으로 유사한 입력, negative는 anchor와 의미적으로 유사하지 않은 입력이 주어진다.
그런 다음 다음과 같은 손실 함수를 최소화한다.
$L = max(d(a,p) - d(a, n) + margin, 0)$
$d$는 거리 함수를 의미하고, a, p, n은 각 입력의 임베딩을 의미한다. margin은 다음 그림으로 이해할 수 있다.

hard negatives는 positive 샘플들이 주로 모여있는 바운더리에 있는 것이고, easy negative는 이 바운더리와 비교적 멀리 떨어져 있는 샘플들을 의미한다. margin은 이 바운더리 간의 거리를 의미하고 미리 설정해주는 값이다.
1. introduction
BERT에서 cross-encoder를 사용하는 것이 문제가 된다. 이는 하나의 네트워크에 두 문장을 입력받는 것을 의미한다. 구체적으로 다음과 같은 이유들이 있다.
- 1. 계산 비용: Cross encoder는 두 문장을 함께 고려하여 유사성을 판단하기 때문에 이는 문장 쌍 별로 계산을 수행해야한다. n개의 문장인 경우 $_{10000}\mathrm{C}_{2}$ 만큼 계산이 필요하다.
- 2. 최적화 어려움: Encoder의 주된 목적은 문장을 임베딩하는 것이기 때문에 두 문장의 유사한지를 계산하기 위해서는 네트워크에 추가적인 계층이 필요하다. 또한 문장 유사도를 위해 네트워크를 최적화 하므로 임베딩의 성능이 저해될 수 있다.
Clustering과 semantic search를 해결하는 일반적인 방법은 각 문장을 벡터 공간에 매핑하려 의미적으로 유사한 문장을 가깝게 배치하는 것이다. 가장 일반적으로 사용되는 방법은 BERT 임베딩이라고 불리는 BERT의 출력 레이어를 평균하는 것 또는 CLS 토큰을 사용하는데, 이러한 방법은 좋지 않은 문장 임베딩을 생성하며 종종 GloVe 임베딩을 평균하는 것보다 나쁘다.
따라서 저자들은 siamese network 구조를 사용해 입력 문장에 대한 고정 크기의 벡터를 유도한다. 그런 다음 코사인 유사도나 맨해튼/유클리드 거리와 같은 유사성 측정을 사용하여 의미적으로 유사한 문장을 찾을 수 있도록 하였다. 또한 이는 1만개의 문장 임베딩 계산을 65시간에서 약 5초로 줄인다.
2. Model
SBERT는 BERT / RoBERTa에 고정된 크기의 문장 임베딩을 얻기 위해 pooling을 추가한다. 저자들은 3가지 pooling 전략을 사용했는데, CLS 토큰 사용, 평균 풀링, max 풀링을 사용하였다. Default는 평균 풀링이다.
클래스 분류를 위한 모델 구조
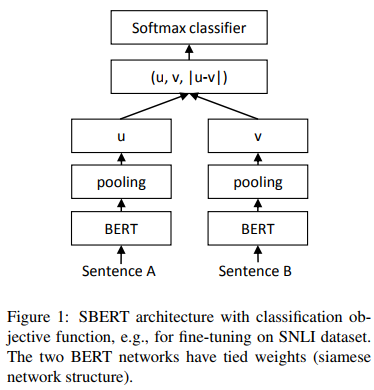
$\left\vert u - v \right\vert$는 임베딩 벡터 $u, v$의 element-wise difference이다. 출력을 수식으로 나타내면 다음과 같다.
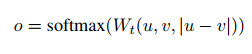
$W_t \in \mathbb{R}^{3n \times k}$는 학습되는 가중치를 의미하고 n은 임베딩 차원을 의미한다. $(u, v, \left\vert u - v \right\vert )$는 3개의 벡터를 연결한 것이다. 따라서 출력 차원은 논문에 나와있지는 않지만 $num_{samples} \times k$일 것으로 생각된다. 목적 함수는 cross-entropy를 사용한다.
회귀를 위한 모델 구조
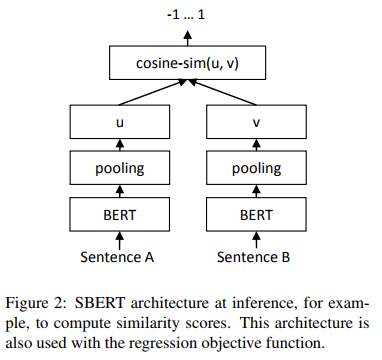
임베딩 벡터 $u, v$의 코사인 유사도를 계산하고 mse 손실을 목적 함수로 사용한다.
훈련 세부 사항
SNLI와 Multi-genre NLI 데이터셋 조합으로 SBERT를 훈련시켰다. SNLI는 contradiction, entailment, 그리고 neutral 라벨이 지정된 57만 개의 문장 쌍으로 이루어진 컬렉션이고, MultiNLI는 43만 개의 문장 쌍을 포함하며, 구두 및 서면 텍스트의 다양한 장르를 다룬다.
3-way softmax-classifier를 목적함수로 fine-tuning을 하고 1 epoch 훈련한다. 배치 크기 16, 학습률 2e-5인 Adam을 사용했으며, 훈련 데이터의 10%에 대한 linear learning rate warm-up을 적용하였다.
3 way라는 용어는 처음봤는데 찾아보니 label이 3개라는 의미였다....



