Vision Transformer와 CNN에 대한 지식이 있다면 논문 내용이 어렵지 않으니 직접 읽어보시는 것을 추천함
CvT: Introducing Convolutions to Vision Transformers
1. Introduction
ViT(Vision Transformer)는 이미지를 겹치지 않는 패치로 분할(예를 들면 16x16)한 뒤 특수한 위치 인코딩과 함께 표준 Transformer layer에 입력한다. 이는 분류를 위해 패치간의 global relationship을 모델링한다.
ViT가 대규모 데이터셋에 대해서는 괜찮은 성능을 보였지만 적은 데이터로 훈련됐을 때는 CNN보다 낮은 성능을 보였다. 이는 ViT가 CNN이 가지고 있는 이미지 데이터에 대한 귀납적 편향이 부족하다고 설명될 수 있다.
이미지는 강력한 2D local structure를 가지고 있으며, 이웃하는 픽셀들은 일반적으로 높은 상관관계를 가진다. 이에 대해 CNN은 다음과 같은 장점이 있다.
- Local recptive fields, shared weights, spatial subsampling을 사용하여 local structure를 잘 포착한다.
- CNN의 계층적 구조는 다양한 level의 시각전 패턴을 학습한다. (저차원 ~ 고차원)
그래서 저자들은 ViT 구조의 두 핵심 부분에 합성곱을 도입한 CvT를 제안한다.
첫 번째로 Transformers를 여러 스테이지로 분할하여 계층적 구조의 Transformers를 형성한다.
- 각 스테이지의 시작은 convolutional token embedding으로 시작된다. 이는 초기 입력 이미지나 스테이지를 거친 뒤 생성되는 2D로 reshape된 token map에 over-lapping되는 convolution 연산을 수행한다. 그런 다음 LayerNorm을 적용한다.
- 이는 CNN의 공간적 다운샘플링처럼 스테이지마다 시퀀스 길이 감소, token feature 차원 증가시킨다.
두 번째로 convolutional transformer block 모듈의 self attention 앞의 linear projection(for Q, K, V)을 합성곱 프로젝션으로 대체한다.
- stride(예를 들면 1에서 2)로 key, value matrix를 다운 샘플링하여 효율성 개선
- 로컬 공간을 더 잘 포착하게 하고, self attention의 semantic 모호성을 감소시킨다고 한다.
추가적으로 CvT에서는 token의 위치 임베딩을 제거한다.
2. CvT

CvT의 구조는 3개의 스테이지로 구성되어 있으며, 각 스테이지는 convolutional token embedding과 convolutional transformer block으로 구성되어 있다. Figure 2(b)를 보면 convolutional transformer block은 convolutional projection, MHSA, MLP로 구성되어 있다.
2.1 Convolutional Token Embedding
입력 이미지나 이전 단계의 출력 token map은 convolutional token embedding을 통과해 $H \times W \times C$의 출력을 낸다. 그럼 다음 $HW \times C$로 flatten된 다음 layer normalization을 적용한다.
합성곱 신경망을 사용하기 때문에 kernel size, stride, channels를 달리하면서 token의 개수나 token의 feature 차원을 조정할 수 있다. 이 방법으로 각 단계에서 점진적으로 token의 시퀀스 길이는 줄이고, feature 차원은 증가시킨다.
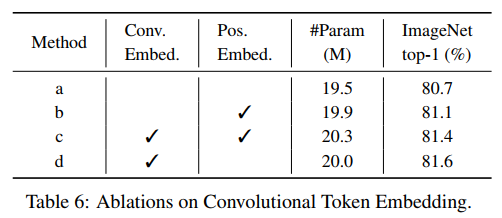
a, d를 비교하면 convolutional token embedding을 사용했을 때 ImageNet top-1 정확도가 0.9% 높다.
2.2 Convolutional Projection for Attention
MHSA의 position-wise linear projection을 depth-wise separable convolution을 대체한다. 이 layer의 목표는 추가적인 local spatial context를 모델링하기 위함과 key, value matrix를 다운샘플링하여 효율적인 측면의 이점을 얻기 위함이다.
DWSC을 적용하는 과정을 설명해보면
- 먼저 Depth-wise Convolution을 수행한다. 기본적인 convolution과 달리 각 채널별로 독립적으로 conv 연산을 수행한다.
- BatchNorm2d 적용
- 그런 다음 Point-wise Convolution(1x1 Convolution)을 수행한다. 이를 통해 각 채널 간의 정보를 결합한다.

위 그림처럼 key, value를 다운샘플링하면 해상도를 줄임으로써 생기는 약간의 성능 감소가 있지만 저자들은 이를 default 옵션으로 사용한다고 한다.

Table 7을 보면 ImageNet top-1 정확도에 대해 key, value를 다운 샘플링한 것이 0.7% 감소하였지만 FLOPs가 약 30% 감소하였다.
Conv proj와 position-wise linear proj을 비교한 결과는 다음과 같다.

스테이지의 projection layer를 conv proj로 대체할 때 마다 성능이 꾸준히 증가한다.
2.3 Removing Positional Embeddings
2.1, 2.2를 도입함으로써 지역 공간 관계를 모델링할 수 있게 됐다고 한다. 이는 위치 임베딩을 제거해도 성능에 영향을 미치지 않게한다.

위 테이블을 보면 DeiT-S의 경우 위치 임베딩을 제거하면 ImageNet top-1 정확도가 1.8% 감소하였지만, CvT-13은 성능에 영향을 미치지 않는다.
2.4 Model Variants
Transformer block의 개수와 feature 차원을 달리하여 3가지 모델을 생성했다. CvT-13, 21은 base model이면 숫자는 block의 총 개수를 의미한다. CvT-W24는 각 단계에 대한 토큰 특성 차원이 더 큰 wide한 모델이다.




