Google에서 2021/06에 발표된 논문이다. 이 포스팅에서는 논문의 모든 섹션을 다루지 않으며 자세한 내용은 paper에서 확인할 수 있다.
Abstract
Computer Vision에서는 주로 어텐션을 합성곱 네트워크와 함께 사용하거나 합성곱 네트워크의 일부 구성 요소를 대체하는데 사용되며 전반적인 구조는 유지된다. 이 논문에서는 CNN을 사용하지 않은 이미지 패치 시퀀스에 직접 적용된 순수한 트랜스포머가 이미지 분류 작업에서 매우 우수한 성능을 발휘할 수 있음을 보여준다. 또한 합성곱 네트워크에 비해 훈련에 필요한 계산 리소스가 상당히 적게 든다.
1. Introduction
자연어 처리에서의 트랜스포머의 성공을 영감으로 삼아, 최소한의 수정으로 표준 트랜스포머를 이미지에 직접 적용하는 실험을 진행하였다. 이를 위해 이미지를 패치로 나누고 이러한 패치들의 선형 임베딩 시퀀스를 트랜스포머의 입력으로 제공한다. 이미지 패치는 NLP에서 토큰과 마찬가지로 처리된다. 그리고 모델을 지도 학습 방식으로 이미지 분류에 훈련시켰다.
중간 규모의 ImageNet과 같은 데이터셋에서 강한 정규화 없이 훈련된 경우, 모델 크기가 비슷한 ResNet보다 몇 퍼센트포인트 낮은 정확도를 얻었다. 트랜스포머는 합성곱 신경망에 내재된 일부 귀납 편향이 부족하므로 충분하지 않은 양의 데이터로 훈련되었을 때 일반화가 잘 이루어지지 않을 수 있다.
여기서 말하는 합성곱 신경망에 내재된 귀납 편향이란 Translation Equivariance(이동 동질성)과 Locality(지역성)을 의미한다. 이동 동질성은 입력데이터에서의 작은 이동이 출력에서도 작은 이동으로 이어지는 성질을 의미한다. 지역성은 CNN이 입력 데이터의 작은 지역 영역에 집중하여 그 지역의 특징을 감지하는 특성을 의미한다.
그러나 더 큰 데이터셋(14M-300M 이미지)에서 훈련된 경우에는 귀납 편향을 능가한다는 것을 발견하였고, 이 Vision Transformer(ViT)는 충분한 규모로 사전 훈련된 후 전이 학습될 때 좋은 결과를 보였다.
2. Method
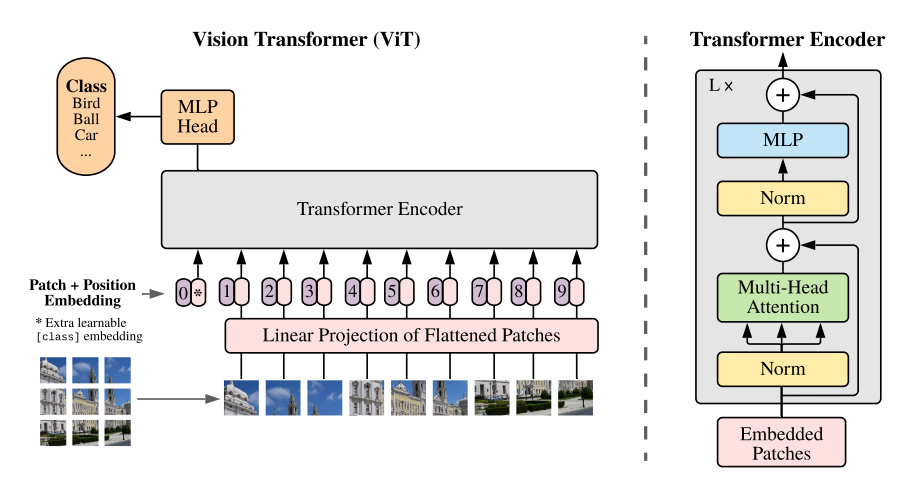
그림 1은 모델의 개요를 보여준다. 이미지를 고정 크기의 패치로 나누고 각각을 선형으로 임베딩한 다음 위치 임베딩을 추가하고 결과 벡터 시퀀스를 표준 트랜스포머 인코더에 공급한다. 분류를 수행하기 위해 시퀀스에 추가로 학습 가능한 "classification token"을 추가하는 방식을 사용한다.
2.1 Vision Transformer(ViT)
표준 트랜스포머는 1차원 시퀀스를 입력으로 받기 때문에 2D 이미지를 처리할 필요가 있다. 2D 이미지 x에 대해서 다음과 같이 조정한다.
$(H, W, C) \longrightarrow (N, P^2 {\cdot}C)$
$(P, P)$는 각 이미지 패치의 해상도를 의미하며, $N=HW/P^2$로 계산되는 패치의 개수이다. 트랜스포머는 모든 레이어에서 일정한 잠재 벡터 크기 D를 사용하므로 패치를 평탄화하고 학습 가능한 선형 투영을 사용하여 D차원으로 매핑한다. 이 투영의 출력을 패치 임베딩이라고 한다.
임베딩된 패치 시퀀스 앞에 학습 가능한 임베딩(CLS 토큰)을 추가한다. Figure 1에서 position 0에 해당하는 부분으로 이미지 representation y로 사용된다. 논문에서는 이를 L번째 인코더의 0번째 출력이라는 의미로 $z_L^0$으로 표현하였다.사전 훈련 및 fine-tuning 중에는 여기에 분류 헤드가 연결된다. 분류 헤드는 사전 훈련 시에는 하나의 은닉 레이어를 가진 MLP로 구현되며, fine-tuning 시에는 단일 선형 레이어로 구현된다.
패치 임베딩에 1D 위치 임베딩을 추가하여 위치 정보를 유지한다.
트랜스포머 인코더는 표준 트랜스포머 인코더와 동일하게 멀티 헤드 셀프 어텐션(MSA)과 MLP 블록이 번갈아 나오는 레이어로 구성되어 있다. 각 블록 앞에 Layernorm(LN)이 적용되고 각 블록 뒤에는 잔차 연결이 이루어진다.
다음은 Vision Transfomer의 작업을 수식으로 표현한 것이다.
- $z_0 = [x_{class}; x_p^1E; x_p^2E; \cdot \cdot \cdot ;x_p^NE] + E_{pos}$
- $z_l^\prime = MSA(LN(z_{l-1})) + z_{l-1}$
- $z_l = MLP(LN(z_l^\prime )) + z_l^\prime $
- $y = LN(z_L^0)$
E의 차원은 $(P^2 \cdot C) \times D$이고 $E_{pos}$의 차원은 $(N + 1) \times D$이다. 1이 더해진 이유는 CLS 토큰이 추가되었기 때문이다. l은 1~L의 값을 가진다.
Vision Transformer는 MLP 레이어만 Translation Equivariance와 Locality를 가지며, 셀프 어텐션 레이어는 전역적이다.
합성곱 신경망을 사용한 하이브리드 아키텍처도 가능한데, 이미지 패치 대신에 입력 시퀀스를 CNN의 feature map으로 사용할 수 있다. 하이브리드 모델에서는 패치 임베딩 투영(D차원 매핑)이 CNN의 feature map에서 추출된 패치에 적용된다.
2.2 Fine Tuning And Higher Resolution
일반적으로 ViT를 큰 데이터셋에서 사전 훈련하고 더 작은 데이터셋을 사용하는 다운스트림 fine-tuning 수행한다. 이를 위해 미리 훈련된 분류 헤드를 제거하고, 0으로 초기화된 $D \times K$의 피드 포워드 레이어를 연결한다. 여기서 K는 하위 작업의 클래스 수이다.
Fine-tuning 때 종종 사전 훈련보다 더 높은 해상도에서 수행하는 것이 유용할 수 있다. 왜냐하면 패치 크기를 유지하면 더 큰 효과적인 시퀀스 길이가 발생하기 때문이다. ViT는 임의의 시퀀스 길이를 처리할 수 있다.
그러나 사전 훈련된 위치 임베딩은 더 이상 의미가 없을 수 있다. 따라서 원래 이미지에서의 위치에 따라 사전 훈련된 위치 임베딩을 2D 보간한다.
3. Experiments
ResNet, ViT, 하이브리드의 표현 학습 능력을 평가한다. 각 모델의 데이터 요구 사항을 이해하기 위해 다양한 크기의 데이터셋에서 사전 훈련하고 여러 벤치마크 작업을 평가한다. 모델의 사전 훈련 비용을 고려할 때, ViT는 대부분의 recognition 벤치마크에서 SOTA 성능을 더 낮은 사전 훈련 비용을 달성한다. 마지막으로, 자가지도 학습을 사용하여 작은 실험을 수행하고, 자가 지도 학습 ViT가 미래에 유망하다는 것을 보여준다.
3.1 Setup

Model Variants
ViT 구성은 BERT에서 사용된 구성을 기반으로 하며 Table 1에 요약되어 있다. "Base"와 "Large" 모델을 BERT에서 채택되었고, 논문에서는 더 큰 "Huge" 모델을 추가하였다. 모델을 나타내는 간략한 표기법을 사용하는데, 예를 들어 ViT-L/16은 "Large" 변형이고 16x16 입력 패치 크기를 의미한다. 패치 크기의 제곱에 반비례하여 Transformer의 시퀀스 길이가 결정되므로, 패치 크기가 더 작은 모델은 계산량이 더 많다.
Training & Fine-tuning
Adam을 사용하여 훈련시킨다. 여기서 $\beta_1=0.9$, $\beta_2=0.999$, 배치 크기는 4096, weight decay는 0.1이다. 다음은 훈련 설정을 요약한 것이다.

ImageNet으로 훈련된 모델은 강력한 정규화가 핵심이다. 그래서 JFT 데이터셋과는 다르게 드롭아웃을 사용했다. 드롭아웃을 qkv-projections 이후의 각 밀집 레이어 다음에 적용되며, 패치 임베딩에 위치 임베딩을 추가한 다음에 적용된다. 모든 훈련은 해상도 224에서 수행된다.
Fine-tuning에서는 모든 모델에 대해 SGD와 모멘텀을 0.9로 사용하며 배치 크기는 512이다. 해상도는 384에서 실행되는데 훈련과 다른 해상도에서 fine-tuning을 실행하는 것이 흔한 관행이라고 한다. ViT는 모든 작업에 대해 해상도 384에서 가장 큰 benefits을 얻는 것을 확인하였다고 한다. 그리고 학습률에 대한 작은 그리드 탐색을 수행하였다. 학습률 범위는 다음과 같다.

검증 세트의 경우 ImageNet은 1%, CIFAR는 2%, Pets와 Flower는 10%를 사용하였다.
3.2 Comparison To State Of The Art
먼저 ViT-H/14와 ViT-L/16을 SOTA CNN과 비교한다. Noisy Student는 ImageNet 및 JFT-300M에서 라벨이 제거된 데이터를 사용하여 semi-supervised 학습을 한 대규모 EfficientNet이다.

위의 표는 3번의 fine-tuning에 대한 정확의 평균과 표준편차를 정리한 표이다. JFT-300M 데이터셋에서 사전 훈련된 ViT 모델은 모든 데이터셋에서 ResNet 기반의 기준 모델을 능가하며, 사전 훈련에 필요한 계산 리소스가 상당히 적다.
3.3 Inspecting Vision Transformer

왼쪽 : ViT-L/32의 초기 선형 임베딩 필터의 RGB 값
가운데 : ViT-L/32의 위치 임베딩의 유사성. 타일은 지정된 행과 열의 패치의 위치 임베딩과 다른 모든 패치의 위치 임베딩 간의 코사인 유사도를 보여준다.
오른쪽 : 각 헤드와 네트워크 깊이 의한 attended area의 크기. 각 점은 한 레이어에서 16개의 헤드 중 하나에 대한 이미지 간의 평균 어텐션 거리를 보여준다.
비전 트랜스포머가 이미지 데이터를 처리하는 방식을 이해하기 위해 내부 표현을 분석한다. 식 1에 해당하는 레이어는 패치를 낮은 차원의 공간으로 선형 프로젝션한다. Figure 7의 왼쪽은 학습된 임베딩 필터의 상위 주성분을 보여준다.
Figure 7의 가운데는 모델이 이미지 내에서 거리를 위치 임베딩의 유사성에 부여하는 것을 보여준다. 즉 가까운 패치끼리는 유사한 위치 임베딩을 가지는 경향이 있다.
셀프 어텐션은 ViT가 이미 최하층에서도 전체 이미지를 대상으로 정보를 통합할 수 있게 해준다. Figure 7의 오른쪽으로 보면 최하층에서 이미 일부 헤드는 이미지의 대부분에 어텐션을 기울이는 것으로 나타났으며, 이는 모델이 정보를 전역적으로 통합하는 능력이 실제로 사용된다는 것을 보여준다. 다른 어텐션 헤드들은 일관적으로 작은 어텐션 거리를 갖고 있다. 이러한 특징은 ResNet을 적용하는 하이브리드 모델에서는 덜 두드러지는 편이며, 이는 이것이 CNN의 초기 합성곱 층과 유사한 기능을 수행할 수 있다는 것을 시사한다.

또한 어텐션 거리는 네트워크 깊이와 함께 증가한다. 이는 Figure 6처럼 전반적으로 모델은 분류에 의미 있는 의미론적으로 관련된 영역에 어텐션을 기울이는 것으로 나타났다.
3.4 Self-Supervision
트랜스포머가 NLP 작업에서 뛰어난 성능을 보이는 이유 중 하나는 대규모 자가 지도(self-supervised) 학습에서 기인한다. 논문에서는 BERT에서 사용되는 마스킹 언어 모델링 작업을 모방하여 자가 지도 사전 훈련을 통해 ViT-B/16 모델로 ImageNet에서 79.9%의 정확도를 달성하였다. 이는 처음부터 훈련하는 것보다 2% 향상된 결과이다. 하지만 지도된 사전 훈련에 비해 4% 적은 결과이다.
마스킹 언어 모델링 작업을 이미지 패치에 적용하는 방법은 다음과 같다. 자가 지도 실험을 위해 마스크된 패치를 예측하는 것을 목표로 삼는다. 이를 위해 패치 임베딩의 50%를 마스킹한다. 마스킹된 임베딩의 80%는 학습 가능한 [mask] 임베딩으로 대체되며, 10%는 무작위 다른 패치 임베딩으로 대체되고, 나머지 10%는 그대로 유지된다. 이 설정은 BERT를 제안한 논문과 매우 유사하다. 마지막으로 마스킹된 패치의 패치 표현을 사용하여 해당 패치의 3비트, 평균 색상(전체 512가지 색상)을 예측한다.
Appendix
리뷰를 하면서 Appendix의 내용을 참고하여 설명한 부분들이 있는데, 추가적으로 Transformer Shape에 관한 부분도 기록해두면 좋겠다고 생각이 들었다.
Transformer Shape

Figure 8은 아키텍처의 다양한 차원을 조정한 것에 대한 결과를 보여준다. 모든 선의 교차점이 기준이되며 이는 $D=1024$, $D_{MLP}=2048$, 패치 크기 32를 갖는 ViT 모델이다. 그림을 보면 깊이를 확장하는 것이 가장 큰 개선을 가져오는 것을 알 수 있다. 이는 64 레이어까지 명확하게 확인되지만 16 레이어 이후 효과가 감소한다. 또한 패치 크기를 줄이는 것 즉, 유효한 시퀀스 길이를 늘리면 견고한 향상이 나타난다.



