1. Introduction
저자들은 이미지 분류를 위한 ViT에서 자가 지도 보조 손실로서 퍼즐 맞추기를 해결하는 방법인 Jigsaw-ViT를 제안하고 있다.
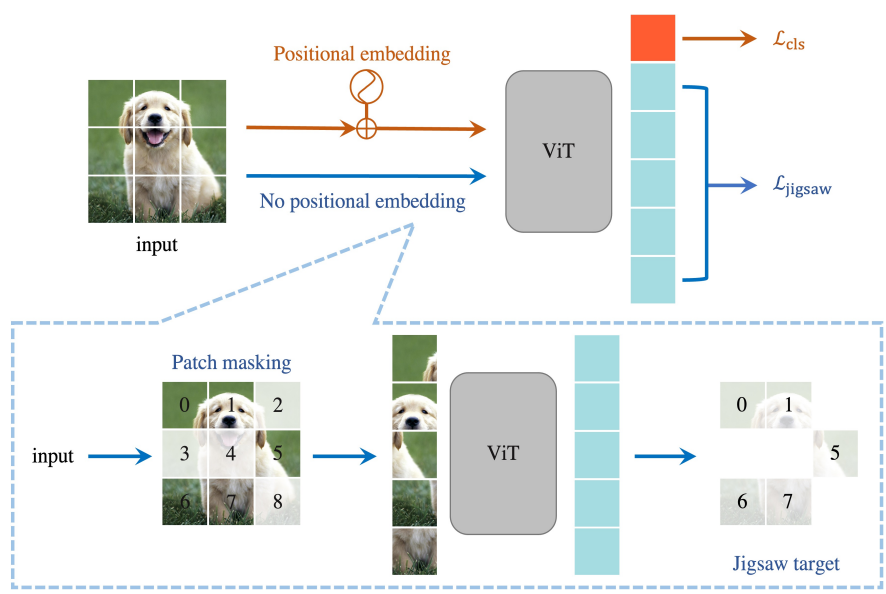
figure 1은 Jigsaw-ViT의 전반적인 overview를 보여주는데, red flow로 표현된 일반적인 CLS 토큰을 사용한 분류 학습에 blue flow로 표현된 $L_{Jigsaw}$를 추가로 학습하는 것이다. 논문에서는 이를 self-supervised 보조 손실로 표현하였다.
일반적인 ViT와 다른 두 가지가 있다.
- 위치 임베딩 제거 : 모델이 명시적인 단서를 활용하여 부정행위를 하는 것을 방지한다.
- 무작위 패치 마스킹 : 마스킹이 안된 패치의 위치만 예측하도록 하여 예측이 여러 특정 패치가 아닌 전역 컨텍스트에 의존하도록 만든다.
2. Method
목표는 표준 분류 및 퍼즐 문제 해결을 동시에 고려하는 ViT 모델을 훈련하는 것이다. 따라서 손실 합은 두 가지 Cross-Entropy Loss를 포함한다.

- $L_{cls}$ : class token에 대한 class prediction loss
- $L_{jigsaw}$ : patch token에 대한 position prediction loss
$\tilde{y}_{pred}$는 position prediction이고 $\tilde{y}$은 그에 상응하는 real position이다. $\eta$는 두 가지 손실의 균형을 위한 하이퍼파라미터이다.
Figure 1에 나와 있듯이 blue flow에서는 1) 위치 임베딩을 제거한다. 그런 다음 2) [0, 1) 범위의 하이퍼파라미터인 $\gamma$만큼 L개의 패치에 대해서 masking을 한다. 여기서 L은 $(HW)/P^2$으로 계산된다. H, W는 입력 이미지의 높이와 너비이고 P는 patch size이다. 예를 들어 높이와 너비가 (8, 8)인 흑백 이미지가 있고 patch size를 2로 설정하면 L=16개의 패치가 만들어진다.
architecture
백본으로 Deit-Small/16을 ditillation token없이 사용한다. 이는 Vit-Small/16과 동일한 구조이다. Deit-Small/16은 임베딩 차원이 D=384이며, 6개의 헤드와 N=12개의 레이어를 가진다. 훈련 이미지 해상도는 (224, 224)이며, 입력으로 14 x 14 패치를 생성한다.
이미지 분류 플로우의 예측 헤드는 인코더 임베딩 차원에서 클래스 수로 매핑되는 단일 완전 연결 레이어이다. 퍼즐 플로우에 대해서는 인코더 이후에 3층 MLP 헤드를 채택한다. 첫 두 층의 차원은 인코더 임베딩 차원과 동일하며, 마지막 층의 출력 차원은 이미지 패치의 총수인 L = 14 x 14이다.
3. Experiments
나머지는 생략하고 ImageNet에 대한 large-scale classification의 성능만 살펴본다.

Training details
Deit와 Jigsaw-ViT에 대해 똑같은 훈련 프로토콜을 적용하였다.
Optimizer로 AdamW을 사용하였고 주요 하이퍼파라미터는 다음과 같다.
- learning rate : 5e-4
- weight decay : 0.05
- batch size : 1024
- epochs : 300
- $\eta = 0.1$
- mask ratio $\gamma = 0.5$
그리고 random augment, MixUp, Cutmix 등의 데이터 증강을 사용하였다.



