Self-training with Noisy Student improves ImageNet classification
1. Introduction
저자들은 unlabeled images를 사용해 ImageNet 정확도를 SOTA로 향상시켰다. 이 이미지의 대부분은 ImageNet의 어떤 카테고리에도 속하지 않는다. 그리고 이 논문의 핵심으로 semi-supervised learning인 Noisy Student Traning 기법을 사용하여 모델을 훈련시켰다.
이 기법은 간단하게 3단계로 구성된다.
- label images로 teacher model을 훈련시킨다.
- 학습된 teacher model을 사용해 unlabeled images에 pseudo label을 생성한다.
- labeled images와 pseudo labeled images를 둘 다 사용해 student model을 훈련시킨다.
그리고 이 알고리즘을 여러번 반복하여 학생 모델을 다시 선생님 모델로 취급하여 unlabeled images에 pseudo label을 생성하고 새로운 학생 모델을 훈련시킨다.
Noisy student training은 두 가지 방식으로 self-training과 knowledge distillation을 개선한다.
- 학생을 선생보다 크거나 적어도 같게 만들어서 학생이 더 큰 데이터셋에서 잘 배울 수 있도록 한다.
- 학생에게 노이즈를 추가하여 노이즈가 섞인 학생이 pseudo label에서 더 열심히 학습하도록 한다. 사용되는 노이즈는 데이터 증강(RandAugment)과 모델 노이즈(dropout, stochastic depth)가 있다.

Noisy student training을 사용해 EfficientNet의 ImageNet top-1 정확도를 SOTA인 88.4%로 향상시켰다. ImageNet-A, C, P는 모드 ImageNet에서 파생된 데이터셋인데 A, P는 강건함(robustness) 그리고 C는 일반화(generalization)을 평가하기 위해 사용된다. 아래는 논문에서 소개한 A, C, P 데이터셋의 일부분이다.

위 그림은 Noisy Student Training으로 학습된 EffNet은 정확하게 예측했지만 w/o Noisy Student Training EffNet은 부정확하게 예측한 이미지들의 일부분이다. 검정색 글씨가 전자의 예측이고 빨간색 글씨가 후자의 예측이다.
2. Noisy Student Training

알고리즘 1은 Noisy Student Training의 개요를 설명한다. Introduction에서 소개한 내용과 거의 비슷하다. 저자들은 학생 모델을 훈련시킬 때 soft pseudo label을 사용했는데, out-of-domain 데이터(confidenc score가 낮은 데이터)에 대해 hard보다 soft가 약간 더 나았기 때문이라고 한다. 아래 그림은 이에 대한 저자들의 실험 결과이다. 결과를 보면 confidence score가 낮을 때 soft 레이블을 사용해 학습한 모델의 정확도가 더 높음을 확인할 수 있다.

Intro에서 한 번 언급했듯이 이 알고리즘은 지식 증류(knowledge distillation)와 self-training을 개선한 알고리즘이다. 일반적으로 지식 증류는 noise가 자주 사용되지 않고 학생 모델은 선생 모델에 비해 작은 모델을 사용한다. 학생 모델에 충분한 용량을 제공하고 노이즈를 통해 어려운 환경에서 학습할 수 있도록 함으로써 학생이 선생보다 우수하도록 만들기 때문에 저자들은 이를 knowledge expansion이라고 말한다.

위 테이블은 noise 적용의 중요성을 보여준다. 어떤 노이즈도 적용되지 않은 학생 모델은 83.2%, SD, Dropout이 적용된 학생 모델은 83.6%, 그리고 Noisy Student Training을 적용한 모델은 83.9%의 정확도를 보인다.
3. Experiments
3.1 Experiments Details
Labeled dataset
ImageNet 데이터셋 사용
Unlabeled dataset
3억 개의 이미지가 있는 JFT 데이터셋에서 ImageNet 검증 셋 이미지를 필터링하여 사용한다. 그런 다음 데이터 필터링 및 균형 조정을 수행한다.
먼저 ImageNet에서 훈련된 EfficientNet-B0로 JFT 데이터셋에 대한 label을 예측한다. 이중에서 confidence score가 0.3 보다 높은 이미지를 선택하는 데, 각 클래스에 대해 최대 13만 개의 이미지를 선택한다. 13만 개 이하의 클래스에 대해서는 일부 이미지를 무작위로 복제하여 13만 개의 이미지를 갖도록 한다. 1000개의 클래스가 있기 때문에 총 이미지 수는 1.3억 개이다. 중복으로 인해 이중에서 고유한 이미지는 8100만 개이다.
Architecture
EfficientNet-B7을 확장한 EfficientNet-L2를 사용한다. 이는 EfficientNet-B7보다 width와 depth는 더 크지만 더 낮은 해상도를 사용한다. 모델의 크기가 크기 때문에 훈련 시간의 EfficientNet-B7의 5배이다.

Training details
레이블된 이미지에 대해서는 기본적으로 배치 크기를 2048로 사용하는데, 메모리가 부족할 경우 512, 1024를 사용해도 성능에는 차이가 없다.
| B4보다 큰 모델 | 작은 모델 | |
| epochs | 350 | 700 |
| learning rate | 0.128 | 0.128 |
| decay | 0.97 / 2.4epochs | 0.97 / 4.8epochs |
추가적으로 train-test resolution discrepancy를 수정하기 위해 작은 해상도로 350 에포크 훈련한 뒤 noise가 없고 레이블이 있는 이미지로 1.5 에포크 동안 fine tuning을 수행한다.
Iterative training
알고리즘 1을 반복하여 새로운 학생 모델을 훈련시킨다고 했었는데, 저자들의 실험 결과에서는 반복을 3번 수행한 경우가 가장 좋았다고 한다. 초기 선생 모델을 B7로 사용하고 그 뒤 학생 모델들은 모두 L2를 사용하였다. 1, 2번 째 iteration에서는 학생 모델에 사용하는 pseudo labeled images를 labeled images의 14배, 3번 째에서는 28배 사용하였다. 아래 테이블은 이에 대한 결과이다.

3.2 ImageNet Results
88.4%의 top-1 정확도를 이전 EfficientNet-B7의 최고 정확도인 85.0%보다 3.4% 높은데, 저자들이 주장하는 요인은 다음과 같다.
- 더 큰 모델 (+0.5%), L2가 B7보다 정확도가 0.5% 높음
- Noisy Student Training (+2.9%)
추가적으로 B0~B7까지 iterative training없이 Noisy Student Training에 대한 실험을 하였다. Iterative training은 적용하지 않았고, 선생과 학생 모델을 각각 동일한 모델을 사용하였다. B0은 label과 unlable의 비율을 동일하게 구성했고, 나머지는 unlabel이 3배 많도록 구성하였다.
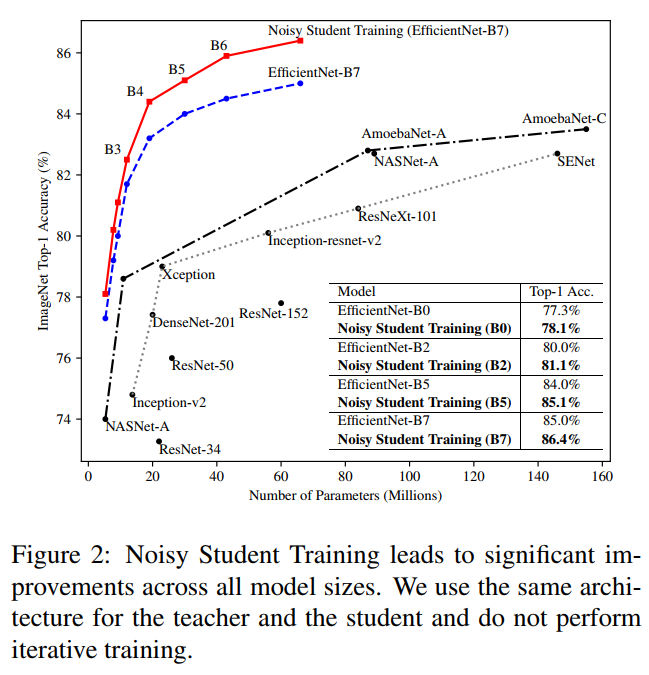
결과를 보면 모든 모델 크기에 대해서 Noisy Student Training을 적용하면 정확도가 약 0.8%의 향상된다.
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] SRGAN (0) | 2024.04.23 |
|---|---|
| [논문 리뷰] Sharpness-Aware Minimization for Efficiently Improving Generalization (0) | 2024.04.21 |
| [논문 리뷰] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2024.04.19 |
| [논문 리뷰] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (0) | 2024.03.29 |
| [논문 리뷰] CvT: Introducing Convolutions to Vision Transformers (0) | 2024.03.12 |



